基于演员-评论家框架的层次化多智能体协同决策方法
主要内容
这篇文章的主要内容是提出了一种基于演员-评论家(Actor-Critic,AC)框架的层次化多智能体协同决策方法,旨在解决复杂作战环境下多智能体协同决策中的任务分配不合理和决策一致性较差的问题。该方法通过将决策过程分为不同层次,并使用AC框架来实现智能体之间的信息交流和决策协同,以提高决策效率和战斗力。在高层次,顶层智能体制定任务决策,将总任务分解并分配给底层智能体。在低层次,底层智能体根据子任务进行动作决策,并将结果反馈给高层次。
研究方法和算法实现:
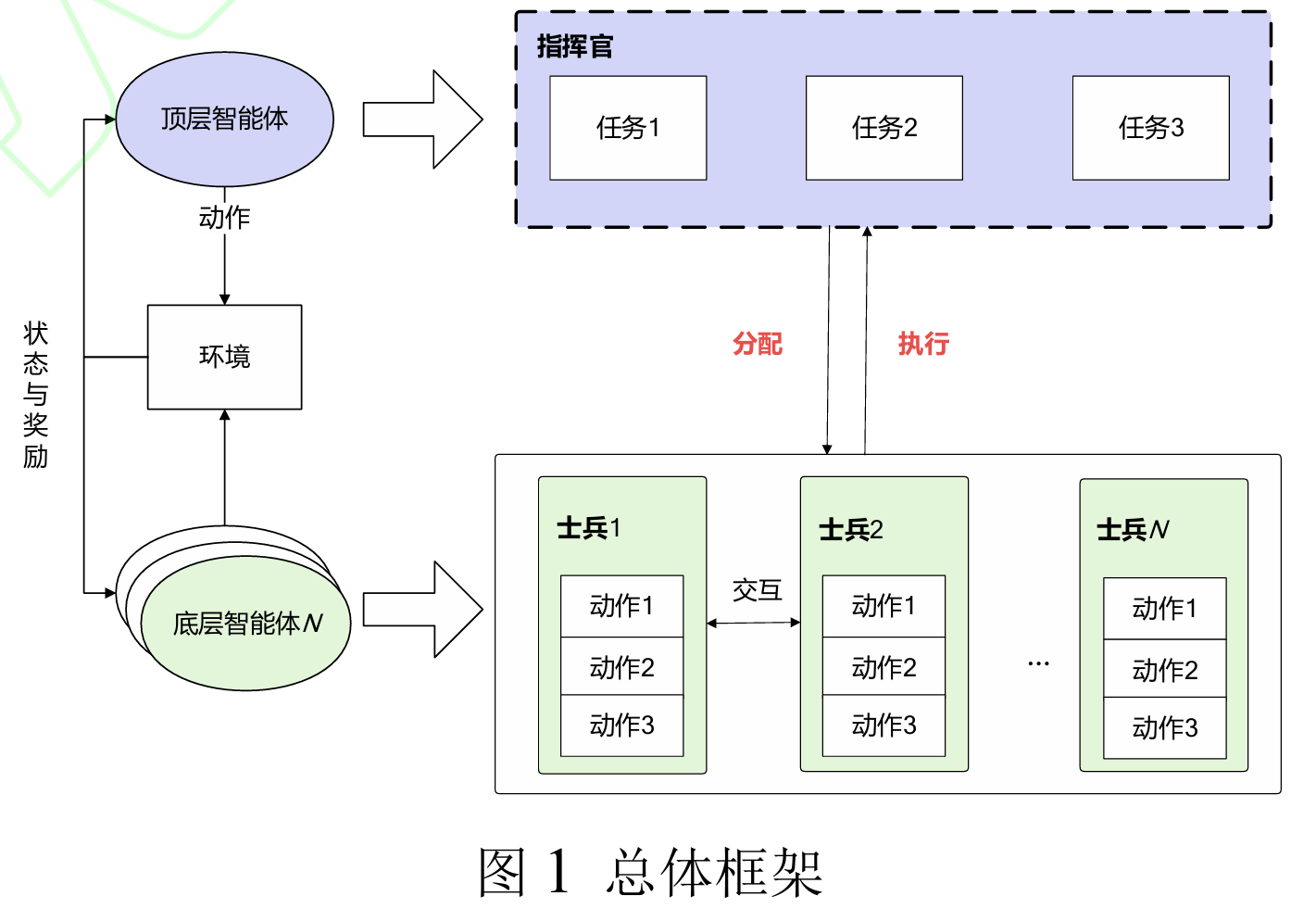
- 决策层次划分:
- 高层次(High Level, HL):顶层智能体负责制定任务决策,将总任务分解并分配给底层智能体。
- 低层次(Low Level, LL):底层智能体根据子任务进行动作决策,并将结果反馈给高层次。
- 状态空间和动作空间的分割:
- 根据层级关系对状态空间和指令空间进行分割,HL决策针对全局作战态势信息下达宏观作战指令,LL决策对执行宏观作战指令的作战编组进行动作操控。
- 上层任务分解
- 给定总任务M,拆分成子任务集{𝑀0,𝑀1,⋯,𝑀𝑖}
- 每一个子任务有任务类型、任务时间、任务状态和作战单元类型,可用one-hot独热码
- 任务类型:主要分为打击任务和巡逻任务,打击任务包含对空拦截、对陆打击,巡逻任务包含空战巡逻、反地面战巡逻
- 任务时间:做离散化处理,用时刻𝑇1和时刻𝑇2来表示
- 任务状态:启动、未启动
- 作战单元:导弹驱逐舰和轰炸机
- 在根据想定场景设计出子任务后,HL需要根据任务类型规划出任务启动时间,并进一步确定任务的启动次序。
- 奖惩函数设计:
- 高层智能体只需要聚焦于 子任务选择是否合适,因此高层智能体的奖励函数HLr设计为当任务合适时给予正奖励回报,反之则为负奖励回报。本文中根据全局任务是否完成判断子任务选择是否正确。
- 基于AC框架的层次化多智能体算法框架:
- 离策略修正的层次化学习(Hierarchical reinforcement learning with off-policy correction, HIRO)[31]算法是一种使用两层策略结构来解决复杂强化学习问题的一种单智能体算法,核心思想是高层策略提出目标,低层策略完成这一目标。
- 采用部分可观察马尔可夫决策过程(POMDP)对环境进行建模。
- 利用深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)算法作为基础,结合多智能体深度强化学习,形成了Hierarchical Multi-Agent Actor-Critic(HMaAC)算法。
- HMaAC算法设计:
- 初始化顶层和底层的Critic网络和Actor网络,以及经验回放缓冲池。
- 通过采样和最小化损失函数更新Critic网络,通过策略梯度更新Actor网络。
- 引入熵约束的概念,最大化策略的熵以学习设置合适的子目标。
- 仿真环境与仿真结果:
- 使用联合作战仿真推演平台作为实验验证环境,进行了2v2、4v4、6v6等不同规模的作战场景实验。
- 实验结果显示,HMaAC算法在多种复杂作战场景下均取得了较好的性能,展现了其在提升军事作战协同决策能力方面的潜力。
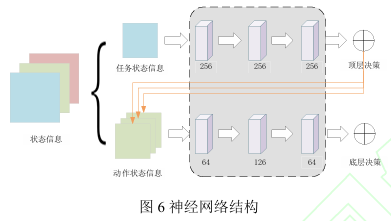
- 网络结构设计和训练参数:
- 设计了上层和下层的神经网络结构,均使用3层全连接层,使用ReLU和Tanh作为激活函数。
- 设定了一系列超参数,如最大episode数量、批处理参数、熵正则项系数等。
- 训练结果分析:
- 对比了HMaAC算法和MADDPG算法在2v2仿真场景中的表现,HMaAC算法在奖励值和收敛速度上优于MADDPG算法。
文章最后指出,尽管HMaAC算法在实验中表现出色,但仍需在实地测试和实战演练中进一步验证其可行性和有效性,同时探讨在更复杂多样化作战环境中的适应性和鲁棒性。
[1]傅妍芳,雷凯麟,魏佳宁,等.基于演员-评论家框架的层次化多智能体协同决策方法[J].兵工学报,2024,45(10):3385-3396.
基于演员-评论家框架的层次化多智能体协同决策方法
http://binbo-zappy.github.io/2024/11/12/多智能体强化学习任务分配/基于演员-评论家框架的层次化多智能体协同决策方法/