2.2 深度学习-Tenserflow实现-吴恩达
Tenserflow实现
1. 模型训练步骤

1.1 Epochs and batches
在上述的 compile 语句中,epochs
的数量被设置为10。这指定了整个数据集在训练过程中应该被应用10次。在训练期间,你会看到描述训练进度的输出,看起来像这样:
1 | |
第一行 Epoch 1/10
描述了模型当前正在运行的是哪个训练周期。为了提高效率,训练数据集被分成了“批次”。在Tensorflow中,默认的批次大小是32。我们的扩展数据集中有200000个样本,或者6250个批次。第二行的符号
6250/6250 [==== 描述了已经执行了哪个批次。
1.2 创建模型

1.3 交叉熵损失函数

- 回归和分类使用不同的损失代价函数
1.4 梯度下降
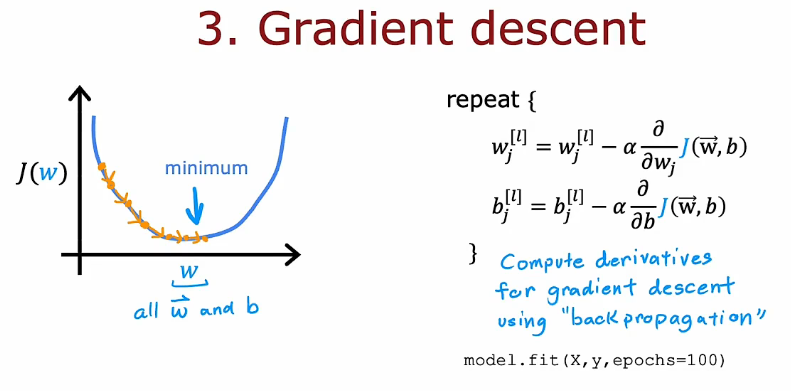
多层感知器:多层神经网路
2. 激活函数
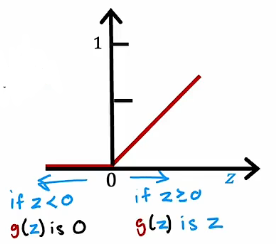
2.1 ReLU Activation
This week, a new activation was introduced, the Rectified Linear Unit (ReLU).
𝑎=𝑚𝑎𝑥(0,𝑧)
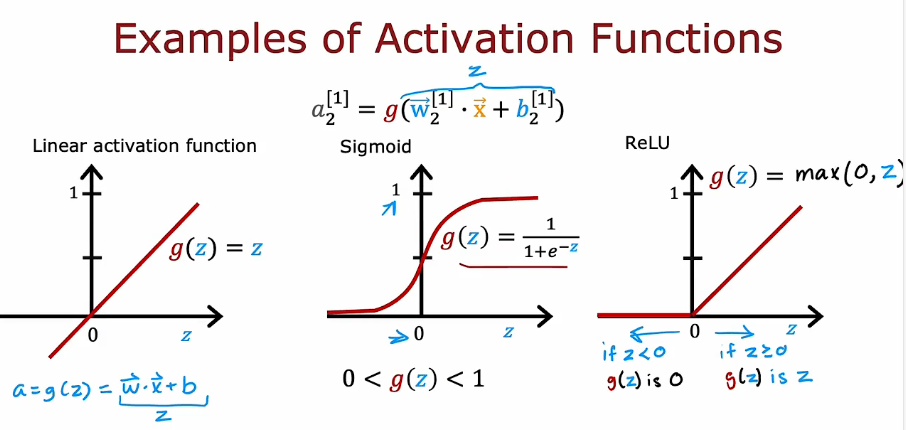
二分类问题,sigmoid激活函数是最自然的选择,输出层使用
回归模型,输出有正有负,预测明天的股票价格,输出层使用线性激活函数
回归模型,输出为非负,预测房屋价格,非负,输出层选择ReLU函数
隐藏层选择Relu函数,ReLU计算速度更快,效率高,但事实证明更重要的第二个原因是ReLU函数仅在图形的一部分变平;左边这里 是完全平坦的,而sigmoid激活函数,它在两个地方变得平坦。梯度下降就会很慢,减慢学习速度
为什么要使用激活函数?
- 若所有层都是用线性激活函数,那就变成了线性回归
3. 多分类问题
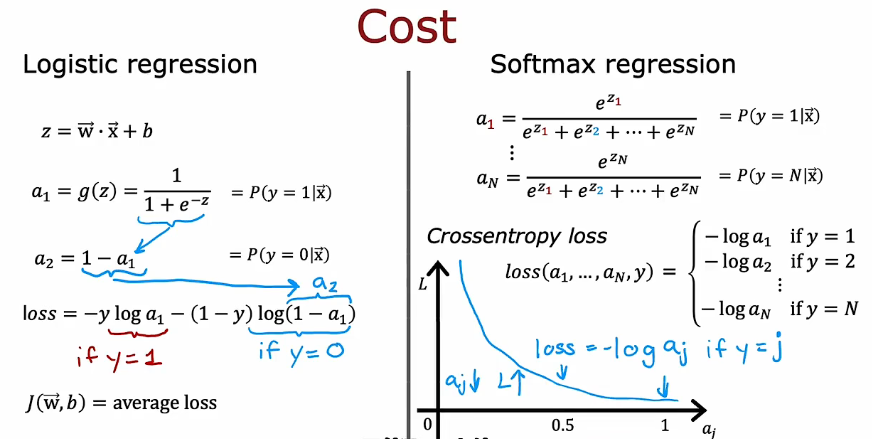
3.1 Softmax函数

3.2 代价函数
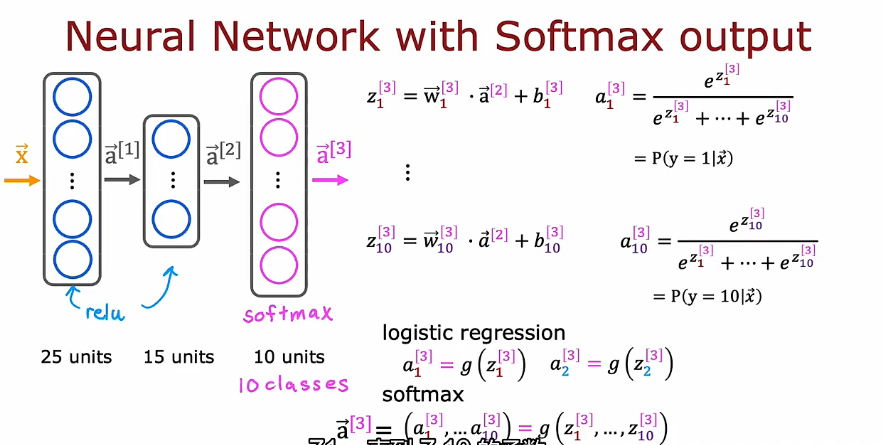
3.3 Tenserflow 实现

3.4 改进实现
避免计算过程中出现过大或者过小值造成计算错误,改进方法在计算过程中进行了重新排列




4. 多标签分类
一个神经网络同时检测多个目标
5. 更快的训练方法
5.1 Adam算法
自动调节α
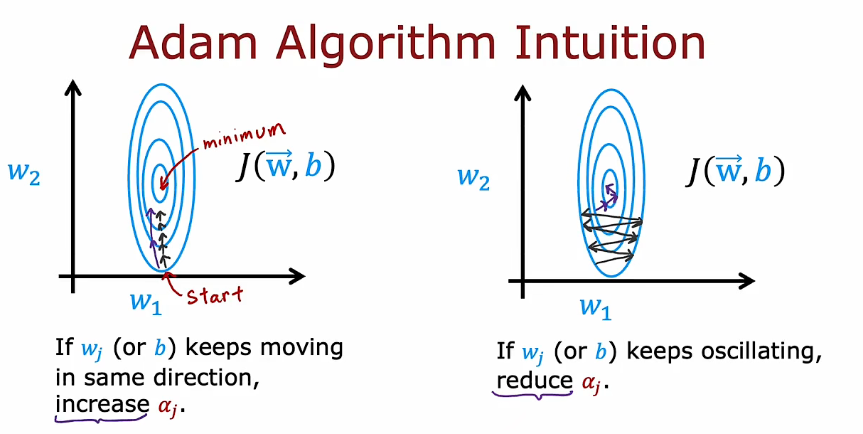

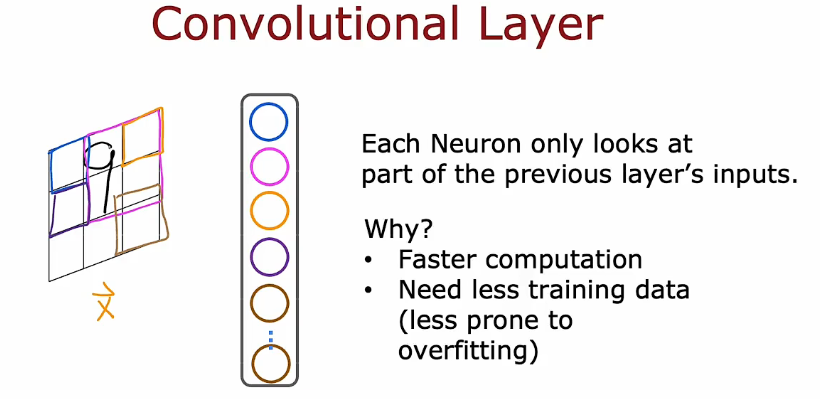
6. 其他的网络层
密集层
卷积层
更快的计算
需要更少的训练数据,不太会过拟合
7. 计算图

2.2 深度学习-Tenserflow实现-吴恩达
http://binbo-zappy.github.io/2024/11/13/ML/class2-week2-深度学习-Tenserflow实现-吴恩达/