2.3 深度学习-在机器学习项目中下一步该做什么-吴恩达
在机器学习项目中下一步该做什么

1. 模型评估
训练集分为两个子集
training set
test set

不包含正则化项


就是相比于之前计算在测试集和训练集上误差的那两个公式,我们更常用模型分类错误的次数除以总的预测次数来表示误差
就是对于逻辑回归来说,可以通过计算误判占比的方法来代表成本函数,比如test set中误判的占比是10%,那么J test就是0.1
1.1 分为三个子集,训练集、交叉验证集、测试集
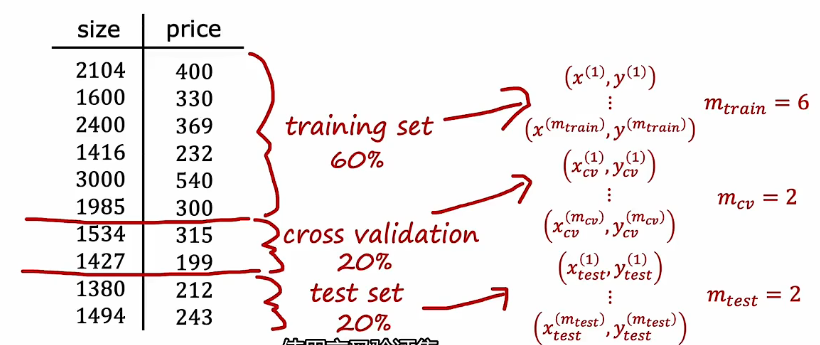

选择最小的交叉验证集误差对应的模型
用测试集来评估泛化误差

1.2 偏差和方差
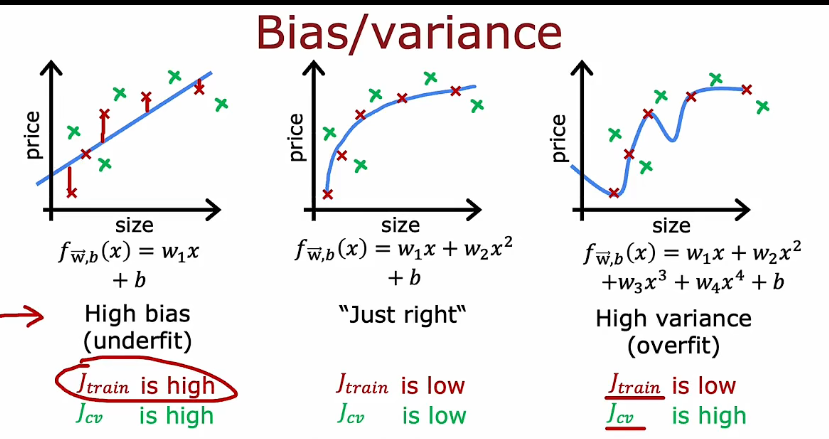
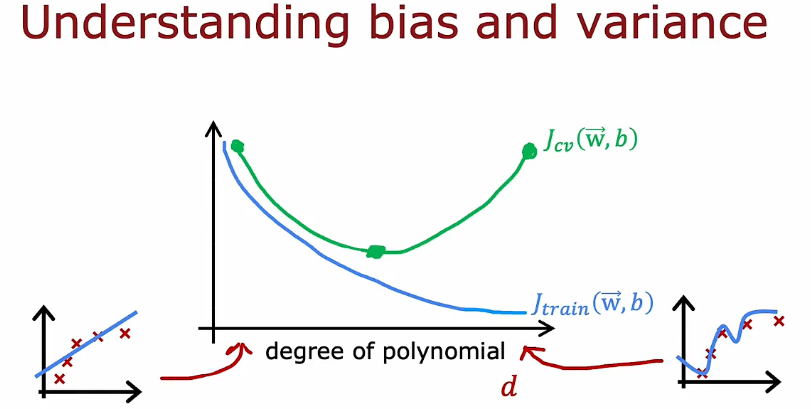

- 正则化如何影响偏差和方差,从而影响算法的性能
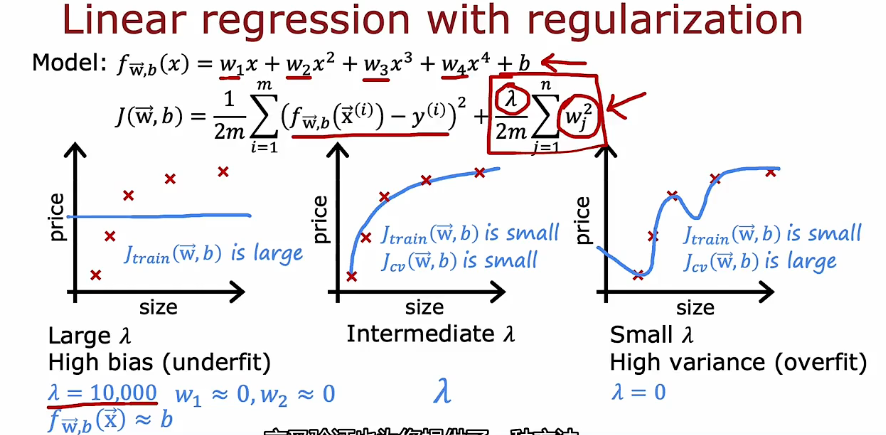

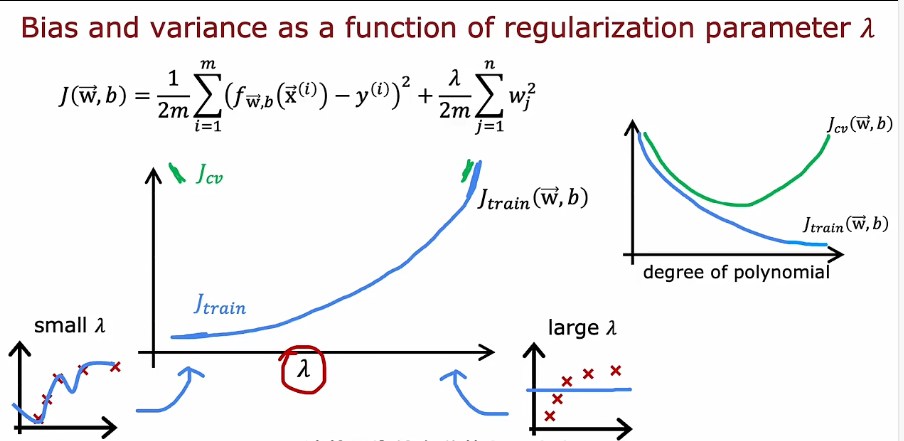
1.3 指定一个用于性能评估的基准

竞争算法
1.4 学习曲线
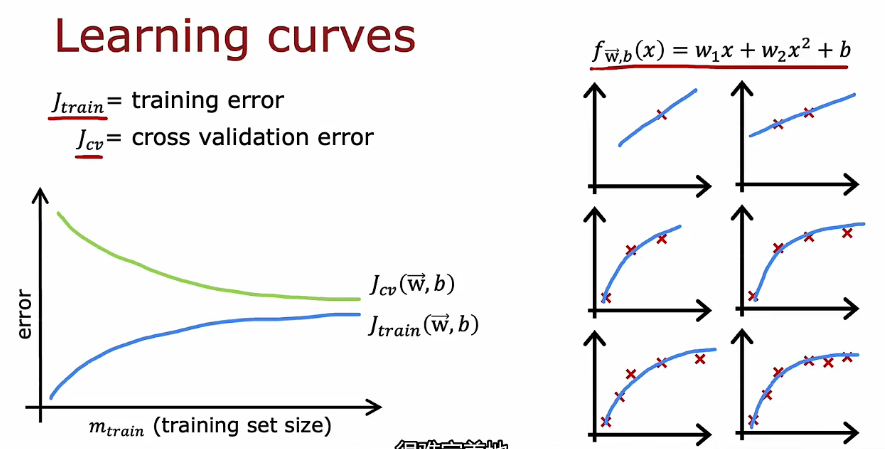
- 训练集变大,误差增大
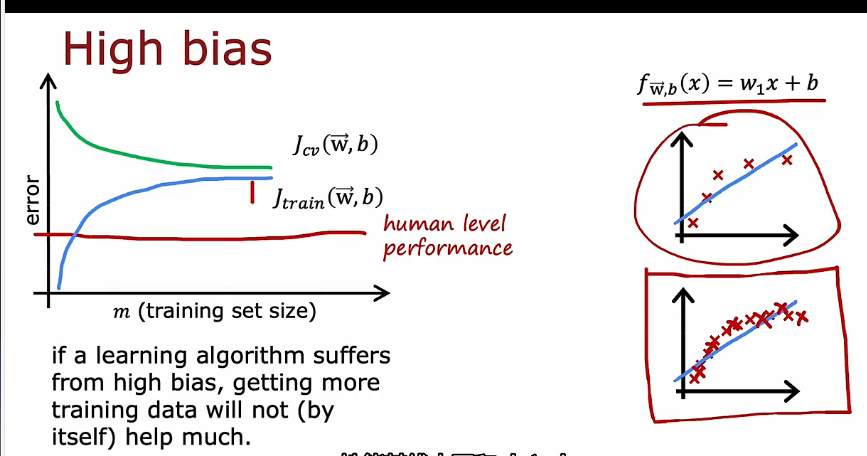
- 这给出了这个结论,也许有点令人惊讶,如果学习算法具有高偏差,获得更多的训练数据本身就没有那么大的希望。

- 所以在这种情况下,可能仅仅通过增加训练集的大小来降低交叉验证误差并让你的算法表现得越来越好,这与高偏差情况不同,在这种情况下你唯一要做的就是获得更多的训练数据,实际上并不能帮助您了解算法性能。
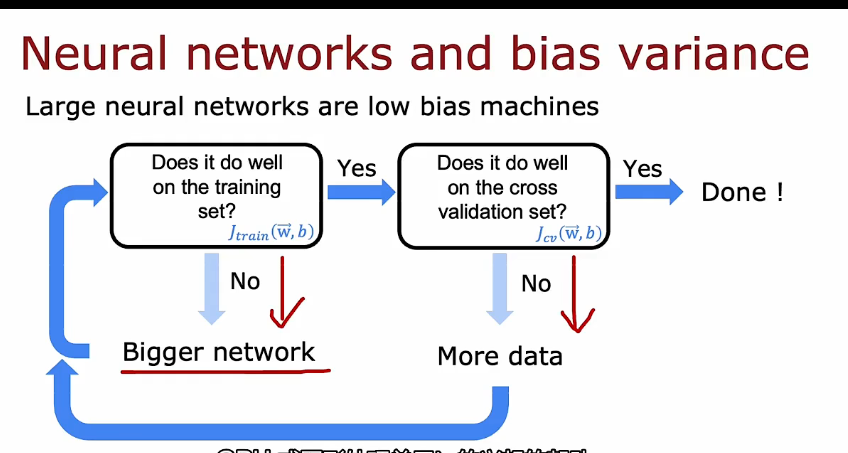
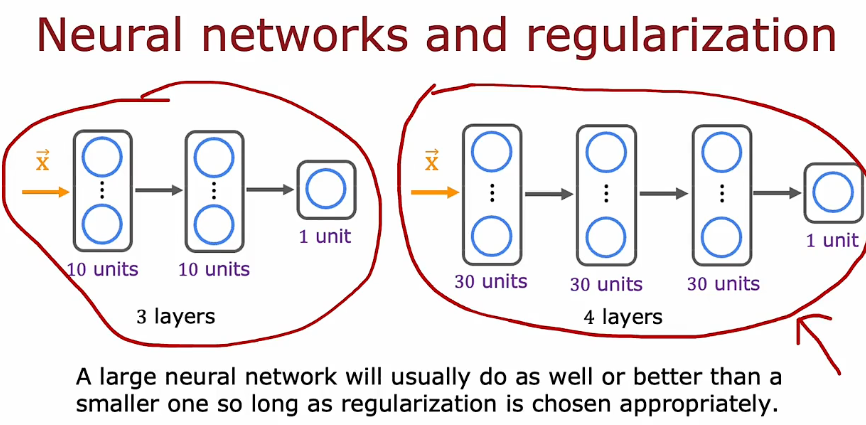
1.5 如何改进

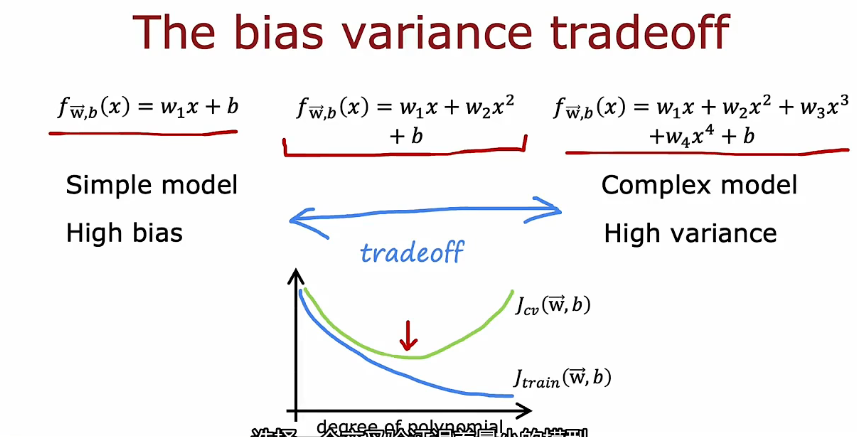

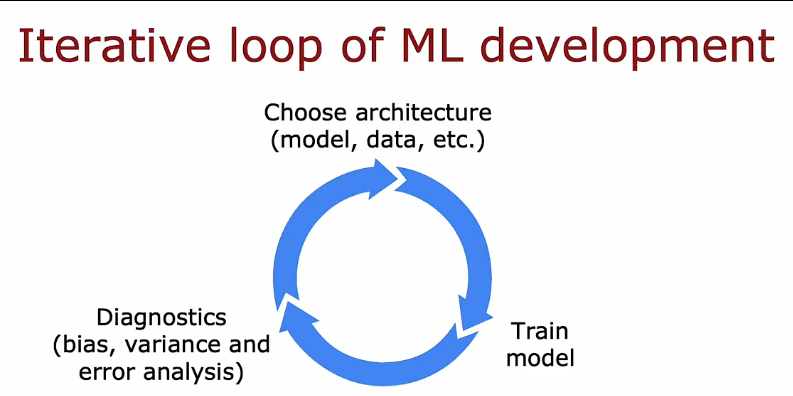
2. 机器学习开发的迭代
- 垃圾邮件分类


2.1 误差分析

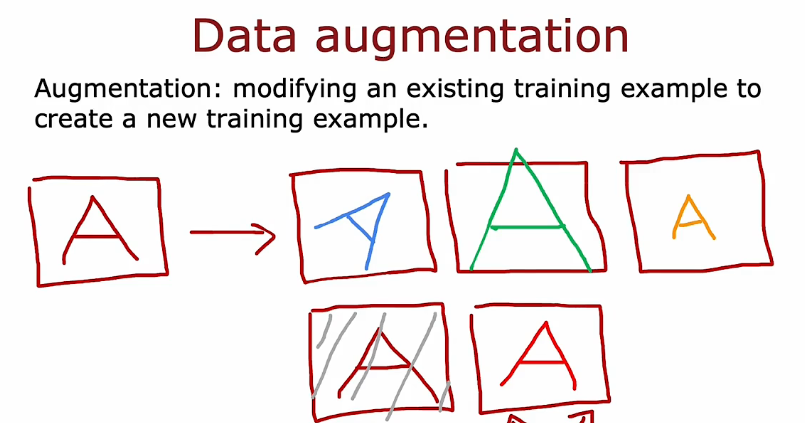
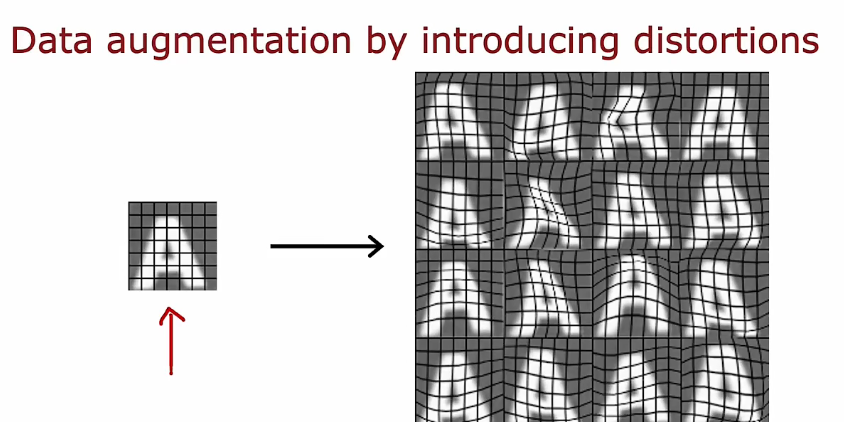
2.2 数据增强
- 旋转图像扭曲放大缩小
- 音频增强



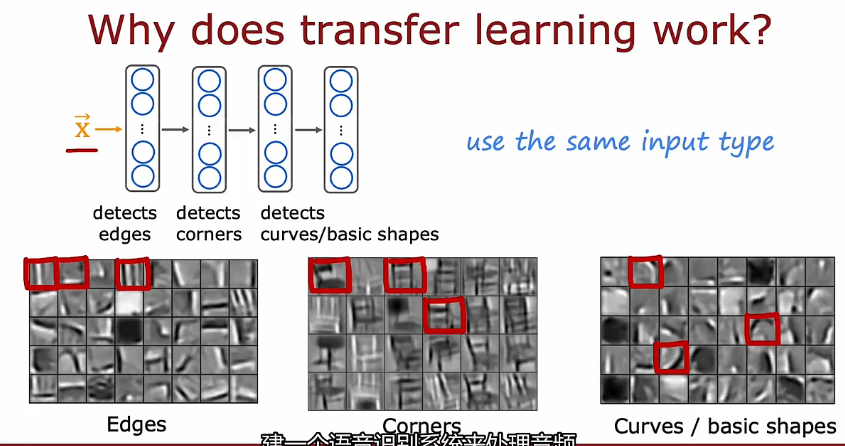
2.3 迁移学习 Transfer learning
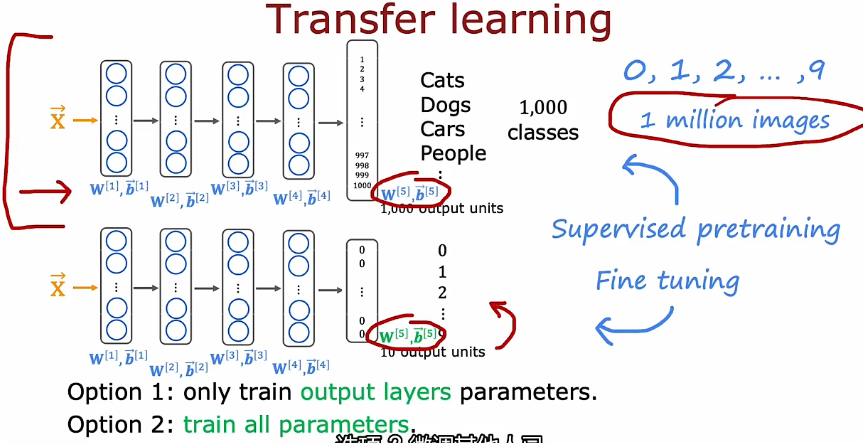
数据集小选择1,数据集大选择2
先在大的数据集训练(监督与训练),再在小的训练称为微调

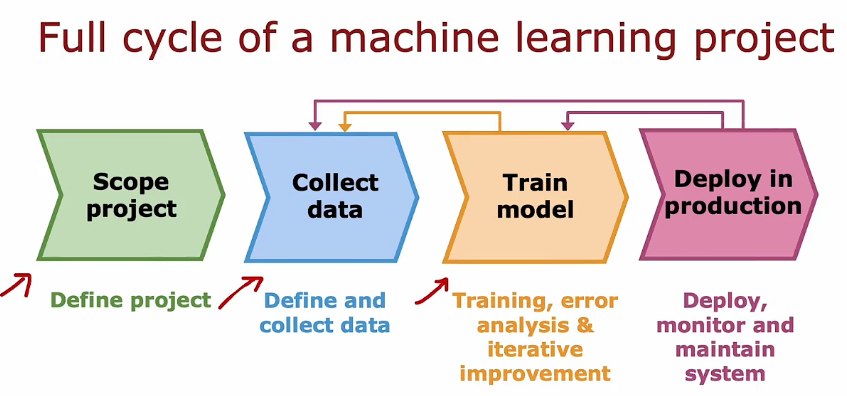
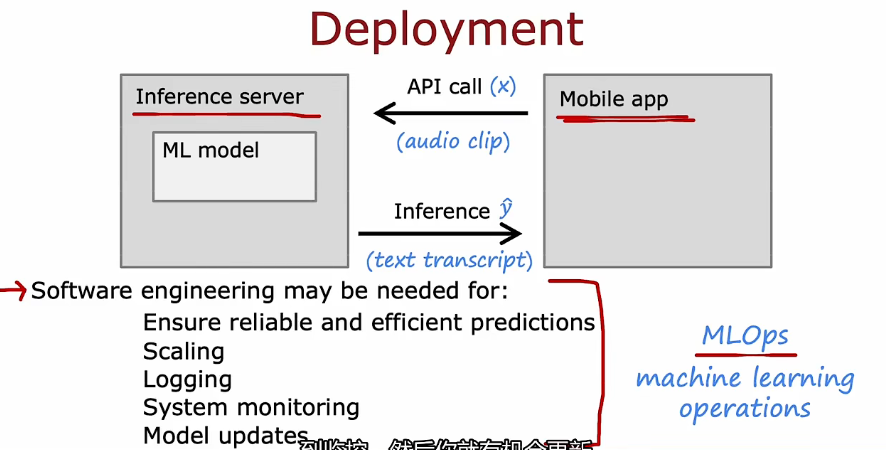
2.4 机器学习项目全周期
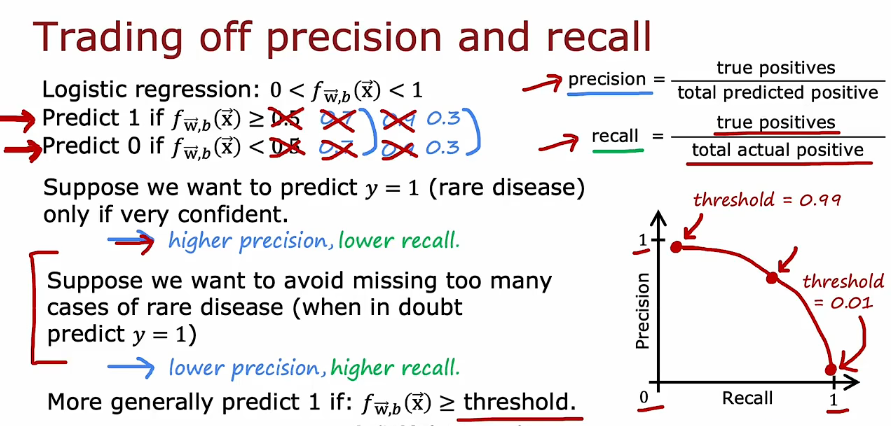
2.5 倾斜数据集的误差指标
- 精确度和召回率

- 精度和召回率
- F1score 更强调P和R中较低的那个 调和平均值

2.3 深度学习-在机器学习项目中下一步该做什么-吴恩达
http://binbo-zappy.github.io/2024/11/14/ML/class2-week3-深度学习-在机器学习项目中下一步该做什么-吴恩达/