2.4 深度学习-决策树-吴恩达
决策树
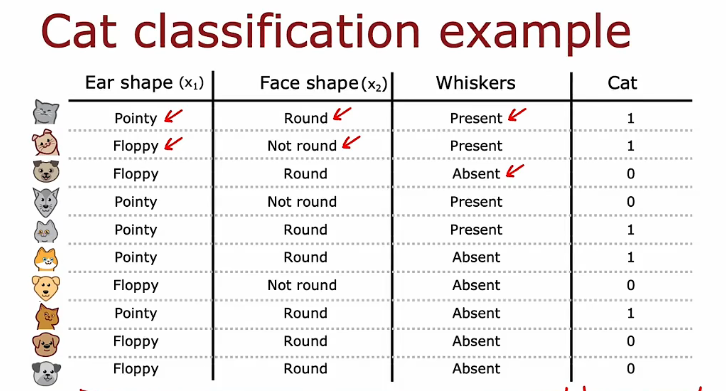
根节点 决策节点 叶节点
决策树学习算法的工作是,从所有可能的决策树中,尝试选择一个希望在训练集上表现良好的树,然后理想地泛化到新数据,例如交叉验证和测试集
1. 学习过程
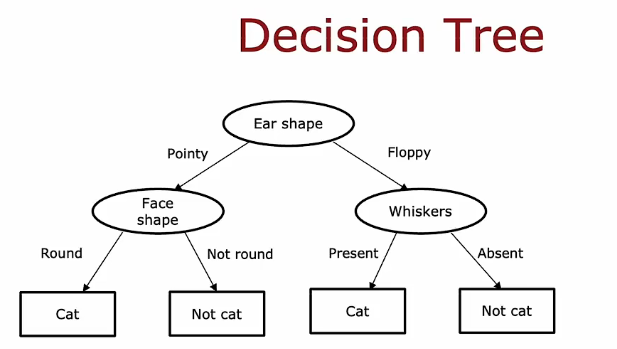
- 决策树学习的第一步是,我们必须决定在根节点使用什么特征。

决策 2:何时停止分裂?
- 当一个节点完全是一类时
- 当分裂一个节点会导致树超过最大深度时
- 当纯度分数的提高低于一个阈值时
- 当节点中的样本数量低于一个阈值时
您可能想要限制决策树深度的一个原因是确保我们的树不会变得太大和笨重,其次,通过保持树小,它不太容易过度拟合。
2. 纯度
2.1 熵 entropy

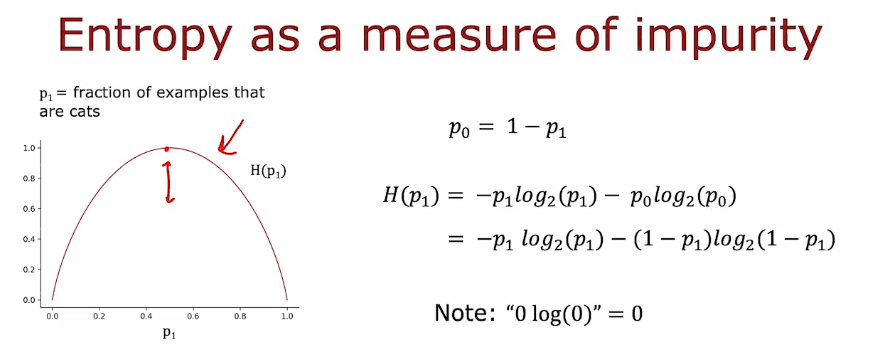
选择拆分信息增益
减少熵
信息增益 分之前的熵减去分后熵的加权平均
停止标准,每次信息增益如果太小停止分类


2.2 整合
- 从根节点开始,包含所有样本
- 计算所有可能特征的信息增益,并选择信息增益最高的特征
- 根据选定的特征划分数据集,并创建树的左分支和右分支
- 持续重复分裂过程,直到满足停止条件:
- 当一个节点完全是一类时
- 当分裂一个节点会导致树超过最大深度时
- 额外分裂的信息增益小于阈值时
- 当节点中的样本数量低于阈值时
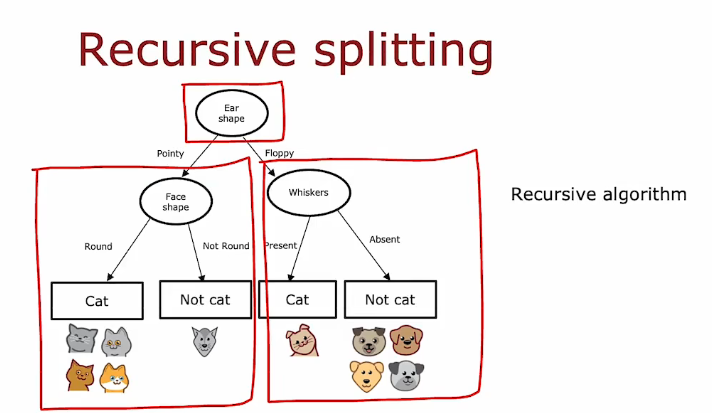
- 递归分类
3. 独热编码 one-hot
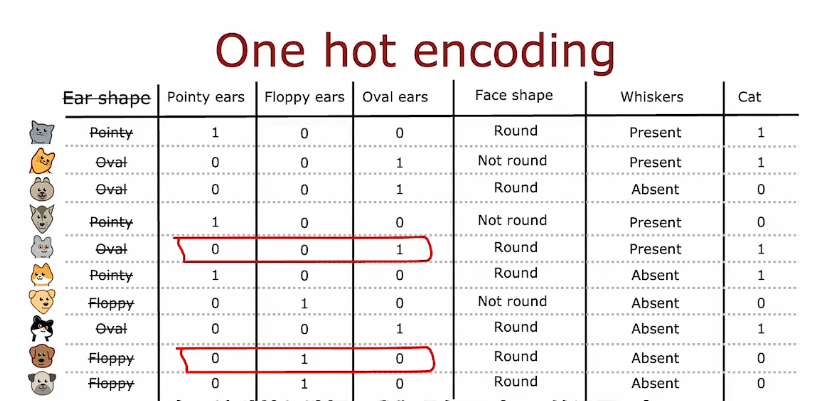
通过one-hot编码,您可以让决策树处理可以采用两个以上离散值的特征,您还可以将其应用于新网络或线性回归或逻辑回归训练。
连续值
尝试不同的阈值,计算纯度
4. 回归树
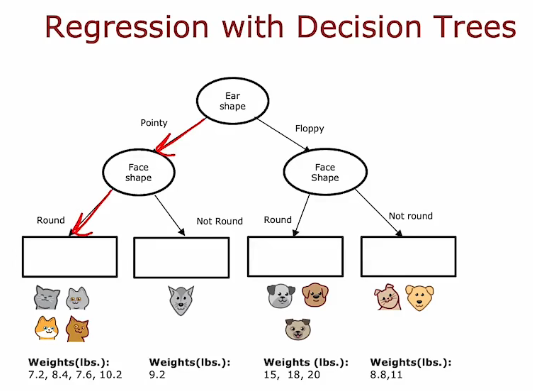
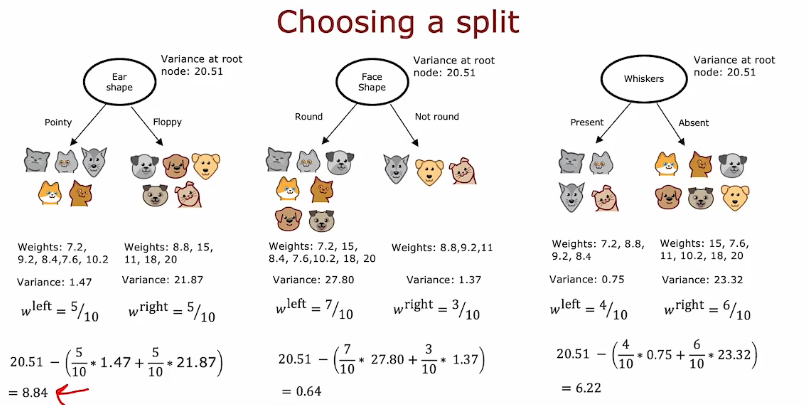
- 尝试减少方差
5. 使用多个决策树
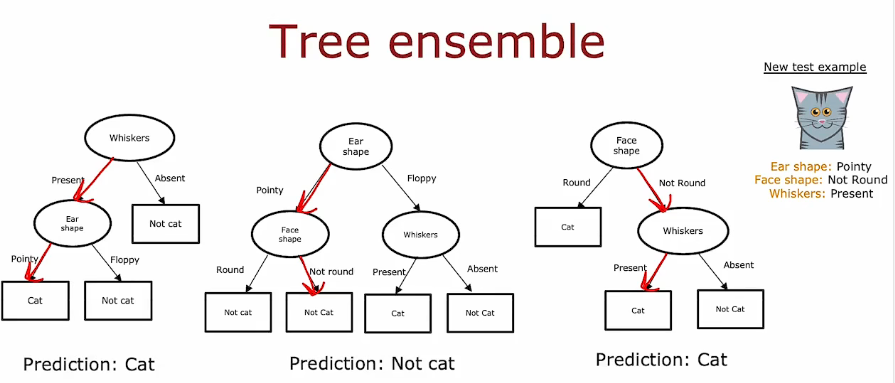
5.1 有放回的采样
构建新的数据集
随机森林算法 Random Forest Algorithm

- 随机化特征选择
- 在每个节点选择用于分裂的特征时,如果有n个特征可用,随机选择一个包含k个特征的子集(k < n),并允许算法仅从这个特征子集中进行选择。
- k的选择(根号n,log2(n))
5.2 XGBoost (extreme Gradient Boosting)
- 提升树的开源实现
- 快速高效的实现
- 默认分裂标准和停止分裂标准的好选择
- 内置正则化以防止过拟合
- 机器学习竞赛中极具竞争力的算法(例如:Kaggle竞赛)

6. 何时使用决策树
- 表格数据


2.4 深度学习-决策树-吴恩达
http://binbo-zappy.github.io/2024/11/14/ML/class2-week4-深度学习-决策树-吴恩达/