3.3 无监督学习-强化学习-吴恩达
强化学习
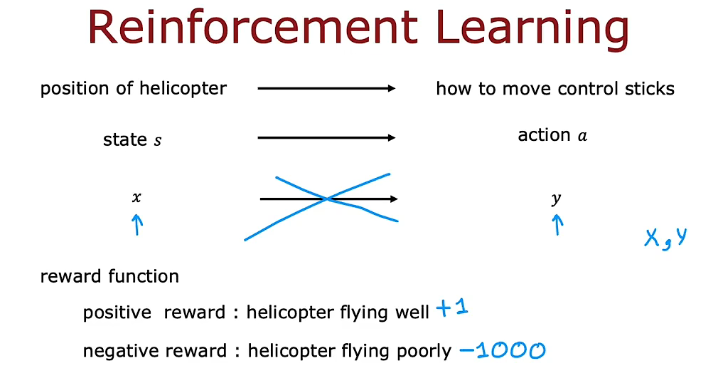

- 状态、动作、奖励和下一个状态(s, a, R(s), s')
1. 回报
- 折扣因子


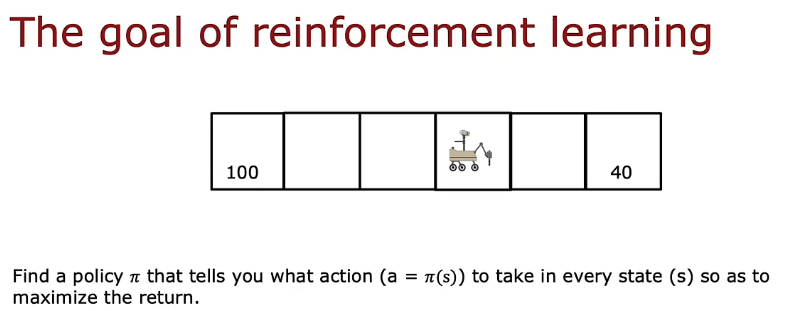
2. 决策
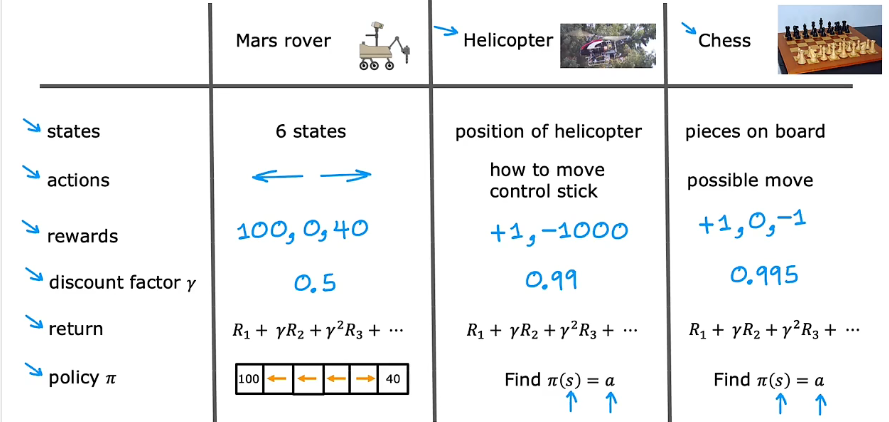
马尔可夫决策过程 MDP
在马尔可夫决策过程中,未来只取决于你现在所处的位置,而不取决于你是如何到达这里的。
3. 状态-动作价值函数

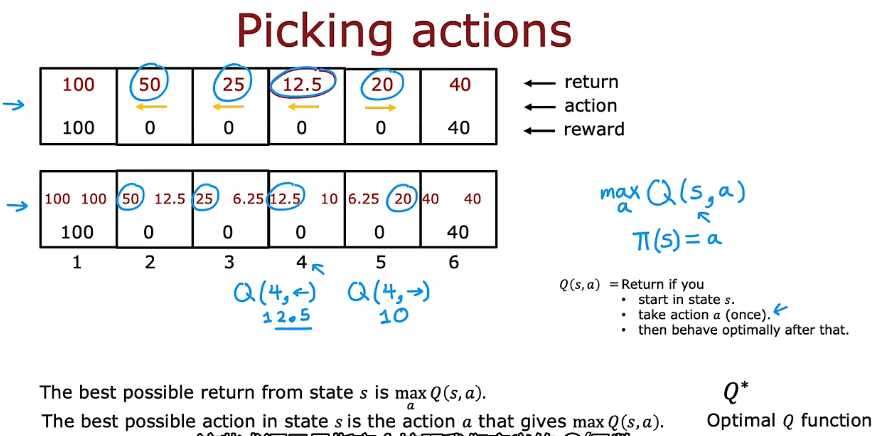
3.1 贝尔曼方程


- 如果你从状态s 开始,你将采取行动a,然后在此之后采取最佳行动,那么你将随着时间的推移看到一些奖励序列。


4. 随机强化学习

5. 连续状态

- 连续马尔可夫 MTP
6. 学习状态值函数
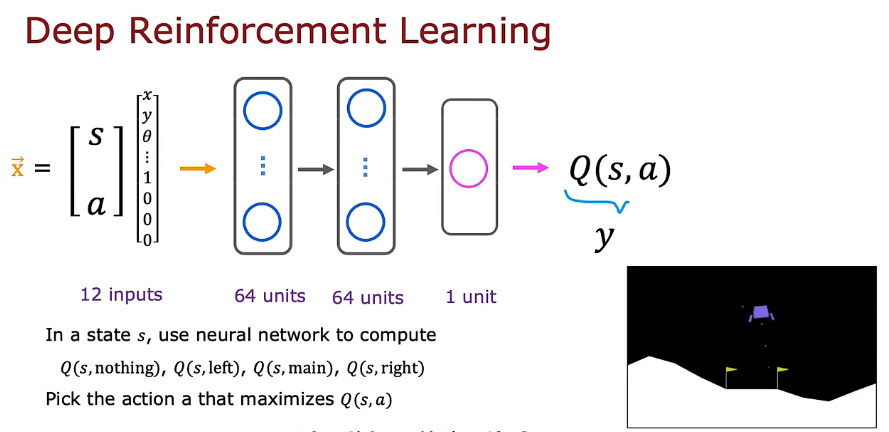

- 不知道Q,随机猜测
7. DQN
- 意思是神经网络里的参数随机初始化,然后(s',a')输入,得到maxQ的预测

- 交给神经网络训练的参数y中一部分是随机初始化神经网络生成的,但还有一部分是包含了当前状态的信息的,所以当训练次数增多后,外部的输入信息会逐步冲刷掉初始化的随机信息,给出真正的Q函数估计。
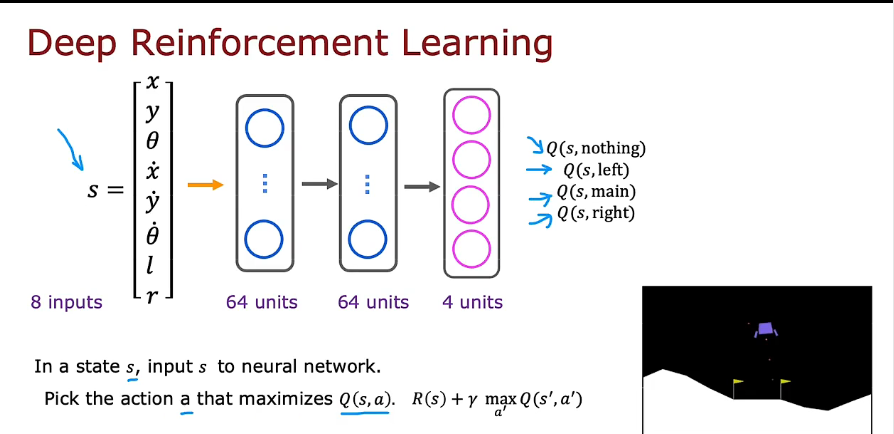
7.1 贪婪算法
- 使用高ε开始,逐步降低直到0.01

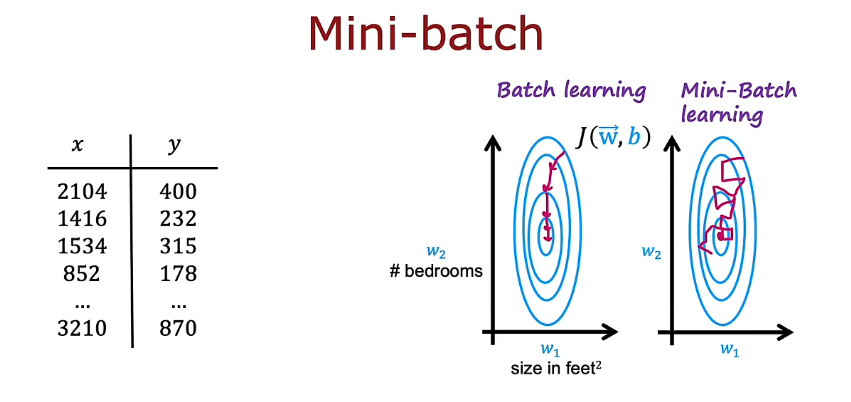
7.2 小批量和软更新



8. 局限性

3.3 无监督学习-强化学习-吴恩达
http://binbo-zappy.github.io/2024/11/14/ML/class3-week3-无监督学习-强化学习-吴恩达/