第三章 内存管理-3.1 内存管理概念
3.1 内存管理
1. 内存的基础知识
1.1 什么是内存? 有何作用?
内存可存放数据, 程序执行前需要先放到内存中才能被CPU处理 -- 缓和CPU与硬盘之间的速度矛盾
在多道程序环境下,系统中会有多个程序并发执行,也就是说会有多个程序的数据需要同时放到内存中。那么,如何区分各个程序的数据是放在什么地方的呢?
- 方案:给内存的存储单元编地址
- 内存中也有一个一个的“小房间”,每个小房间就是一个“存储单元"
- 内存地址从0开始,每个地址对应一个存储单元
- 如果计算机“按字节编址",则每个存储单元大小为 1字节,即 1B,即 8个二进制位
- 如果字长为16位的计算机“按字编址”,则每个存储单元大小为 1个字,每个字的大小为 16 个二进制位
补充知识:
- 210 = 1K(千)
- 220 = 1M(兆,百万)
- 230 = 1G(十亿,千兆)
- 注:
有的题目会告诉我们内存的大小,让我们确定地址长度应该是多少(即要多少个二进制位才能表示相应数目的存储单元)
- Q: 一台手机/电脑 有 4GB 内存,是什么意思?
- A: 是指该内存中可以存放 4 * 230个字节。如果是按字节编址的话,也就是有 4 * 230 = 232个“小房间”,这么多“小房间”,需要 232个地址才能一一标识,所以地址需要用 32 个二进制位来表示(0~232 -1)
1.2 指令的工作原理
指令: 操作码 + 若干参数(可能包含地址参数)
指令的工作基于“地址”。每个地址对应一个数据的存储单元
我们写的代码要翻译成CPU能识别的指令。这些指令会告诉CPU应该去内存的哪个地址读/写数据,这个数据应该做什么样的处理
1.3 逻辑地址 vs 物理地址
物理地址(绝对地址)即内存中的实际地址
程序经过编译、链接后生成的指令中指明的是逻辑地址(相对地址)
- 即:相对于进程的起始地址而言的地址
1.4 从写程序到程序运行
编译:由编译程序将用户源代码编译成若干个目标模块(编译就是把高级语言翻译为机器语言)
链接:由链接程序将编译后形成的一组目标模块,以及所需库函数链接在一起,形成一个完整的装入模块
装入(装载):由装入程序将装入模块装入内存运行
1.5 链接的三种方式
- 静态链接
- 在程序运行之前,先将各目标模块及它们所需的库函数连接成一个完整的可执行文件(装入模块),之后不再拆开
- 装入时动态链接
- 将各目标模块装入内存时,边装入边链接的链接方式
- 运行时动态链接
- 在程序执行中需要该目标模块时,才对它进行链接
- 其优点是便于修改和更新,便于实现对目标模块的共享
1.6 装入的三种方式
- 绝对装入
- 在编译时,如果知道程序将放到内存中的哪个位置,编译程序将产生绝对地址的目标代码,装入程序按照装入模块中的地址,将程序和数据装入内存
- 绝对装入只适用于单道程序环境
- 程序中使用的绝对地址,可在编译或汇编时给出,也可由程序员直接赋予。通常情况下都是编译或汇编时再转换为绝对地址
- 静态重定位(可重定位装入)
- 编译、链接后的装入模块的地址都是从0开始的,指令中使用的地址、数据存放的地址都是相对于起始地址而言的逻辑地址。可根据内存的当前情况,将装入模块装入到内存的适当位置。装入时对地址进行“重定位”,将逻辑地址变换为物理地址(地址变换是在装入时一次完成的)
- 静态重定位的特点是在一个作业装入内存时,必须分配其要求的全部内存空间,如果没有足够的内存,就不能装入该作业。作业一旦进入内存后,在运行期间就不能再移动,也不能再申请内存空间。
- 动态重定位(动态运行时转入)
- 编译、链接后的装入模块的地址都是从0开始的。装入程序把装入模块装入内存后,并不会立即把逻辑地址转换为物理地址,而是把地址转换推迟到程序真正要执行时才进行。因此装入内存后所有的地址依然是逻辑地址。这种方式需要一个重定位寄存器的支持
- 重定位寄存器:存放装入模块存放的起始位置
- 采用动态重定位时允许程序在内存中发生移动
- 可将程序分配到不连续的存储区中
- 在程序运行前只需装入它的部分代码即可投入运行,然后在程序运行期间,根据需要动态申请分配内存
- 便于程序段的共享,可以向用户提供一个比存储空间大得多的地址空间
2. 内存管理的概念
2.1 内存管理
- 操作系统作为系统资源的管理者,当然也需要对内存进行管理,要管些什么呢?
- 操作系统负责内存空间的分配与回收
- 操作系统需要提供某种技术从逻辑上对内存空间进行扩充
- 操作系统需要提供地址转换功能,负责程序的逻辑地址与物理地址的转换
- 操作系统需要提供内存保护功能。保证各进程在各自存储空间内运行,互不干扰
2.2 内存空间的分配与回收
操作系统要怎么记录哪些内存区域已经被分配出去了,哪些又还空闲?
很多位置都可以放,那应该放在哪里?
当进程运行结束之后,如何将进程占用的内存空间回收?
分配方式:
- 连续分配管理方式
- 连续分配:指为用户进程分配的必须是一个连续的内存空间
- 单一连续分配、固定分区分配、动态分区分配
- 非连续分配管理方式
- 非连续分配:指为用户进程分配的可以是一些分散的内存空间
- 基本分页存储管理、基本分段存储管理、段页式存储管理
- 连续分配管理方式
2.3 内存空间的扩充
实现虚拟性
实现内存空间扩充的相关技术: 覆盖技术、交换技术、虚拟存储技术
2.4 地址转化
为了使编程更方便,程序员写程序时应该只需要关注指令、数据的逻辑地址。而逻辑地址到物理地址的转换(这个过程称为地址重定位)应该由操作系统负责,这样就保证了程序员写程序时不需要关注物理内存的实际情况
三种装入方式:
- 绝对装入: 单道程序阶段,此时还没产生操作系统
- 可重定位装入(静态重定位): 用于早期的多道批处理操作系统
- 动态运行时转入(动态重定位): 现代操作系统
2.5 内存保护
- 内存保护可采取两种方法:
- 方法一:在CPU中设置一对上、下限寄存器,存放进程的上、下限地址。进程的指令要访问某个地址时,CPU检查是否越界
- 假设进程1的逻辑地址空间为 0~179;实际物理地址空间为 100~279
- 则上限寄存器存放100, 下限寄存器存放279
- 方法二:采用重定位寄存器(又称基址寄存器)和界地址寄存器(又称限长寄存器)进行越界检查。重定位寄存器中存放的是进程的起始物理地址。界地址寄存器中存放的是进程的最大逻辑地址
- 假设进程1的逻辑地址空间为 0~179;实际物理地址空间为 100~279
- 则重定位寄存器存放100, 界地址寄存器存放179
- CPU先通过界地址寄存器判断指令有没有越界, 没有的话再通过重定位寄存器计算物理地址
- 方法一:在CPU中设置一对上、下限寄存器,存放进程的上、下限地址。进程的指令要访问某个地址时,CPU检查是否越界
3. 覆盖与交换
3.1 覆盖技术
早期的计算机内存很小,比如 IBM 推出的第一台PC机最大只支持 1MB 大小的内存。因此经常会出现内存大小不够的情况。后来人们引入了覆盖技术,用来解决“程序大小超过物理内存总和”的问题
覆盖技术的思想:
- 将程序分为多个段(多个模块),常用的段常驻内存,不常用的段在需要时调入内存
- 内存中分为一个“固定区”和若干个“覆盖区”
- 需要常驻内存的段放在“固定区”中,调入后就不再调出(除非运行结束)
- 不常用的段放在“覆盖区”,需要用到时调入内存,用不到时调出内存
- 程序按照自身逻辑结构,让那些不可能同时被访问的程序段共享同一个覆盖区
缺点:
- 必须由程序员声明覆盖结构,操作系统完成自动覆盖。对用户不透明,增加了用户编程负担
- 覆盖技术只用于早期的操作系统中,现在已成为历史
3.2 交换(对换)技术
内存空间紧张时,系统将内存中某些进程暂时换出外存,把外存中某些已具备运行条件的进程换入内存(进程在内存与磁盘间动态调度)
中级调度(内存调度),就是要决定将哪个处于挂起状态的进程重新调入内存
思考:
- 应该在外存(磁盘)的什么位置保存被换出的进程?
- 具有对换功能的操作系统中,通常把磁盘空间分为文件区和对换区两部分
- 文件区主要用于存放文件,主要追求存储空间的利用率,因此对文件区空间的管理采用离散分配方式
- 对换区空间只占磁盘空间的小部分,被换出的进程数据就存放在对换区。由于对换的速度直接影响到系统的整体速度,因此对换区空间的管理主要追求换入换出速度,因此通常对换区采用连续分配方式(学过文件管理章节后即可理解),总之,对换区的I/O速度比文件区的更快
- 什么时候应该交换?
- 交换通常在许多进程运行且内存吃紧时进行,而系统负荷降低就暂停
- 例如:在发现许多进程运行时经常发生缺页,就说明内存紧张,此时可以换出一些进程;如果缺页率明显下降,就可以暂停换出
- 应该换出哪些进程?
- 可优先换出阻塞进程;可换出优先级低的进程;
- 为了防止优先级低的进程在被调入内存后很快又被换出,有的系统还会考虑进程在内存的驻留时间…
- 应该在外存(磁盘)的什么位置保存被换出的进程?
注意:PCB 会常驻内存,不会被换出外存
4. 连续分配管理方式
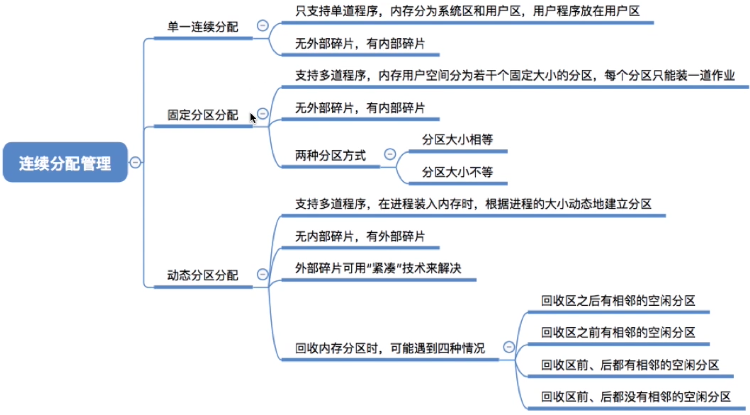
- 连续分配:指为用户进程分配的必须是一个连续的内存空间
4.1 单一连续分配
在单一连续分配方式中,内存被分为系统区和用户区。系统区通常位于内存的低地址部分,用于存放操作系统相关数据;用户区用于存放用户进程相关数据。内存中只能有一道用户程序,用户程序独占整个用户区空间
优点:实现简单;无外部碎片;可以采用覆盖技术扩充内存;不一定需要采取内存保护(eg:早期的 PC 操作系统 MS-DOS)
缺点:只能用于单用户、单任务的操作系统中;有内部碎片;存储器利用率极低
- 内部碎片:分配给某进程的内存区域中,如果有些部分没有用上
- 外部碎片:内存中的某些空闲分区由于太小而难以利用
4.2 固定分区分配
20世纪60年代出现了支持多道程序的系统,为了能在内存中装入多道程序,且这些程序之间又不会相互干扰,于是将整个用户空间划分为若干个固定大小的分区,在每个分区中只装入一道作业,这样就形成了最早的、最简单的一种可运行多道程序的内存管理方式
分区大小相等
- 缺乏灵活性,但是很适合用于用一台计算机控制多个相同对象的场合(比如:钢铁厂有n个相同的炼钢炉,就可把内存分为n个大小相等的区域存放n个炼钢炉控制程序)
分区大小不等
- 增加了灵活性,可以满足不同大小的进程需求。根据常在系统中运行的作业大小情况进行划分
- 比如:划分多个小分区、适量中等分区、少量大分区
操作系统需要建立一个数据结构 -- 分区说明表,来实现各个分区的分配与回收。每个表项对应一个分区,通常按分区大小排列。每个表项包括对应分区的大小、起始地址、状态(是否已分配)。当某用户程序要装入内存时,由操作系统内核程序根据用户程序大小检索该表,从中找到一个能满足大小的、未分配的分区,将之分配给该程序,然后修改状态为“已分配”
优点:实现简单,无外部碎片
缺点:
- 当用户程序太大时,可能所有的分区都不能满足需求,此时不得不采用覆盖技术来解决,但这又会降低性能
- 会产生内部碎片,内存利用率低
4.3 动态分区分配(可变分区分配)
这种分配方式不会预先划分内存分区,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。因此系统分区的大小和数目是可变的
思考:
- 系统要用什么样的数据结构记录内存的使用情况?
- 可以通过空闲分区表或空闲分区链这两种数据结构记录内存使用情况
- 空闲分区表: 每个空闲分区对应一个表项。表项中包含分区号、分区大小、分区起始地址等信息
- 空闲分区链: 每个分区的起始部分和末尾部分分别设置前向指针和后向指针。起始部分处还可记录分区大小等信息
- 当很多个空闲分区都能满足需求时,应该选择哪个分区进行分配?
- 把一个新作业装入内存时,须按照一定的动态分区分配算法,从空闲分区表(或空闲分区链)中选出一个分区分配给该作业
- 由于分配算法算法对系统性能有很大的影响,因此人们对它进行了广泛的研究
- 如何进行分区的分配与回收操作?
- 假设系统采用的数据结构是“空闲分区表”
- 分配
- 可以根据实际分配情况, 对空闲分区表进行分区大小修改、删除表项等操作
- 回收
- 可以根据实际回收情况, 对空闲分区表进行合并表项(回收的区域有相邻的空白表项)、新增表项等操作
- 注:各表项的顺序不一定按照地址递增顺序排列,具体的排列方式需要依据动态分区分配算法来确定
- 分配
- 假设系统采用的数据结构是“空闲分区表”
- 系统要用什么样的数据结构记录内存的使用情况?
动态分区分配没有内部碎片,但是有外部碎片
- 如果内存中空闲空间的总和本来可以满足某进程的要求,但由于进程需要的是一整块连续的内存空间,因此这些
- “碎片”不能满足进程的需求。可以通过紧凑(拼凑,Compaction)技术来解决外部碎片
- "紧凑"之后需要把进程的起始地址修改, 进程的起始地址存放在PCB当中, 进程上CPU运行之前,会把进程的起始地址放到重定位寄存器里
动态分区分配应该采用动态运行时装入(动态重定位)
- 因为通过紧凑技术会导致进程起始地址发生变化, 而动态重定位允许程序在内存中发生移动
5. 动态分区分配算法
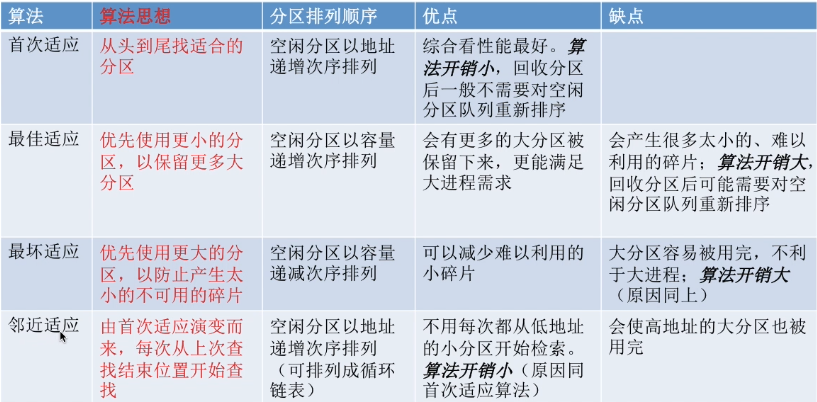
动态分区分配算法: 在动态分区分配方式中, 当很多个空闲分区都能满足需求时,应该选择哪个分区进行分配
5.1 首次适应算法(First Fit)
算法思想:每次都从低地址开始查找,找到第一个能满足大小的空闲分区
如何实现:空闲分区以地址递增的次序排列。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区
优点:首次适应算法每次都要从头查找,每次都需要检索低地址的小分区。 但是这种规则也决定了当低地址部分有更小的分区可以满足需求时, 会更有可能用到低地址部分的小分区,也会更有可能把高地址部分的大分区保留下来(最佳适应算法的优点)
5.2 最佳适应算法(Best Fit)
算法思想:由于动态分区分配是一种连续分配方式,为各进程分配的空间必须是连续的一整片区域。因此为了保证当“大进程”到来时能有连续的大片空间,可以尽可能多地留下大片的空闲区,即,优先使用更小的空闲区
如何实现:空闲分区按容量递增次序链接。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区
缺点:每次都选最小的分区进行分配,会留下越来越多的、很小的、难以利用的内存块。因此这种方法会产生很多的外部碎片
5.3 最坏适应算法(Worst Fit)
又称 最大适应算法(Largest Fit)
算法思想:为了解决最佳适应算法的问题 -- 即留下太多难以利用的小碎片,可以在每次分配时优先使用最大的连续空闲区,这样分配后剩余的空闲区就不会太小,更方便使用
如何实现:空闲分区按容量递减次序链接。每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区
缺点:每次都选最大的分区进行分配,虽然可以让分配后留下的空闲区更大,更可用,但是这种方式会导致较大的连续空闲区被迅速用完。如果之后有“大进程”到达,就没有内存分区可用了
5.4 邻近适应算法(Next Fit)
算法思想:首次适应算法每次都从链头开始查找的。这可能会导致低地址部分出现很多小的空闲分区,而每次分配查找时,都要经过这些分区,因此也增加了查找的开销。如果每次都从上次查找结束的位置开始检索,就能解决上述问题
如何实现:空闲分区以地址递增的顺序排列(可排成一个循环链表)。每次分配内存时从上次查找结束的位置开始查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区
缺点:邻近适应算法的规则可能会导致无论低地址、高地址部分的空闲分区都有相同的概率被使用,也就导致了高地址部分的大分区更可能被使用,划分为小分区,最后导致无大分区可用(最大适应算法的缺点)
综合来看,四种算法中,首次适应算法的效果反而更好
6. 基本分页存储管理的概念
- 非连续分配:指为用户进程分配的可以是一些分散的内存空间
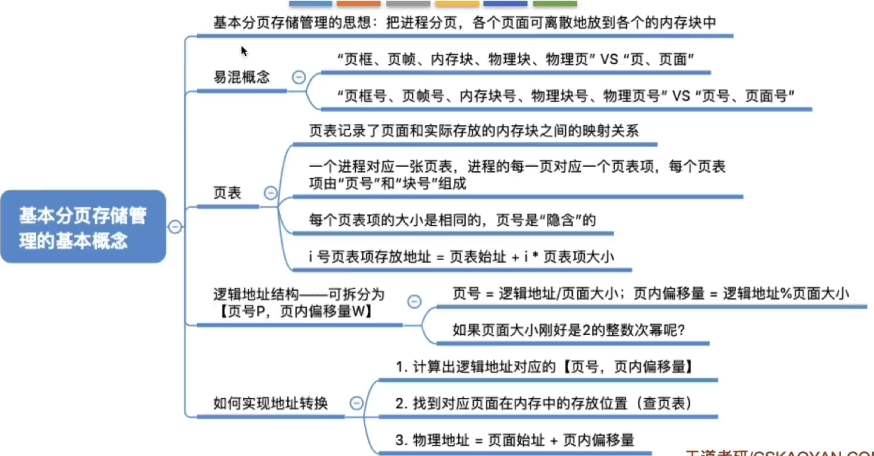
6.1 什么是分页存储?
将内存空间分为一个个大小相等的分区(比如:每个分区4KB),每个分区就是一个“页框(PageFrame)”(页框=页帧=内存块=物理块=物理页面)。每个页框有一个编号,即“页框号”(页框号=页帧号=内存块号=物理块号=物理页号),页框号从0开始
将进程的逻辑地址空间也分为与页框大小相等的一个个部分,每个部分称为一个“页”或“页面” 。每个页面也有一个编号,即“页号”,页号也是从0开始
注意区分 页框 vs 页 的概念
操作系统以页框为单位为各个进程分配内存空间。进程的每个页面分别放入一个页框中。也就是说,进程的页面与内存的页框有一一对应的关系。各个页面不必连续存放,可以放到不相邻的各个页框中
- 注:进程的最后一个页面可能没有一个页框那么大。也就是说,分页存储有可能产生内部碎片,因此页框不能太大,否则可能产生过大的内部碎片造成浪费
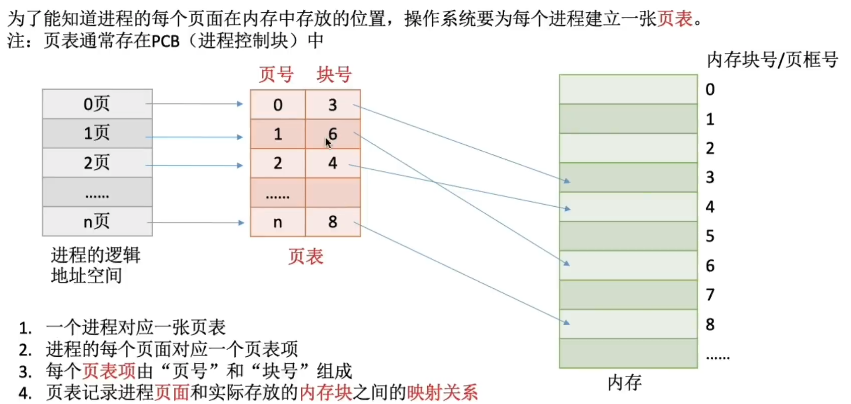
6.2 页表
- 为了能知道进程的每个页面在内存中存放的位置,操作系统要为每个进程建立一张页表
- 注:页表通常存在PCB(进程控制块)中
6.3 每个页表项多大?占几个字节?
Eg:假设某系统物理内存大小为 4GB,页面大小为 4KB,则每个页表项至少应该为多少字节?
内存块大小=页面大小=4KB= 212B
- 4GB 的内存总共会被分为 232 / 212 = 220个内存块
- 内存块号的范围应该是 0 ~ 220 -1
- 内存块号至少要用 20 bit 来表示
- 内存按字节编址, 则至少要用3B来表示块号(3*8=24bit)
- 注意:页表记录的只是内存块号,而不是内存块的起始地址!
- j 号内存块的起始地址 = j * 内存块大小
- 重要考点:计算机中内存块的数量 → 页表项中块号至少占多少字节
- 注意:页表记录的只是内存块号,而不是内存块的起始地址!
页表项连续存放,因此页号可以是隐含的,不占存储空间(类比数组)
- 假设页表中的各页表项从内存地址为 X 的地方开始连续存放,如何找到页号为 i 的页表项?
- i 号页表项的存放地址 = X + i * 页表项大小
6.4 如何通过页表实现逻辑地址到物理地址的转换?
- 进程在内存中连续存放时,操作系统是如何实现逻辑地址到物理地址的转换的?
- 重定位寄存器:指明了进程在内存中的起始位置
- 物理地址 = 进程在内存中的起始位置 + 逻辑地址
- 逻辑地址相对于起始位置的“偏移量”
- 将进程地址空间分页之后,操作系统该如何实现逻辑地址到物理地址的转换?
- 特点:虽然进程的各个页面是离散存放的,但是页面内部是连续存放的
- 如果要访问逻辑地址 A,则:
- 确定逻辑地址A 对应的“页号”P
- 找到P号页面在内存中的起始地址
- 通过查找页表,找到页号P对应的内存块号,计算出内存块号在内存中的起始地址
- 确定逻辑地址A 的“页内偏移量”W
- 逻辑地址A 对应的物理地址 = P号页面在内存中的起始地址 + 页内偏移量W
6.5 如何确定一个逻辑地址对应的页号、页内偏移量?
Eg:在某计算机系统中,页面大小是50B。某进程逻辑地址空间大小为200B,则逻辑地址 110 对应的页号、页内偏移量是多少?
- 页号 = 110 / 50 = 2
- 页内偏移量 = 110 % 50 = 10
页号 = 逻辑地址 / 页面长度 (取除法的整数部分)
页内偏移量 = 逻辑地址 % 页面长度(取除法的余数部分)
逻辑地址 可以拆分为(页号,页内偏移量)
当页面大小刚好是2的整数幂时:

- 总结:页面大小 刚好是 2的整数幂 有什么好处?
- 逻辑地址的拆分更加迅速 -- 如果每个页面大小为 2KB,用二进制数表示逻辑地址,则末尾 K 位即为页内偏移量,其余部分就是页号。因此,如果让每个页面的大小为 2 的整数幂,计算机硬件就可以很方便地得出一个逻辑地址对应的页号和页内偏移量,而无需进行除法运算,从而提升了运行速度
- 物理地址的计算更加迅速 -- 根据逻辑地址得到页号,根据页号查询页表从而找到页面存放的内存块号,将二进制表示的内存块号和页内偏移量拼接起来,就可以得到最终的物理地址
6.6 逻辑地址结构
- 页面大小刚好是2的整数幂时:

- Tips:有些奇葩题目中页面大小有可能不是2的整数次幂,这种情况还是得用最原始的方法计算:
- 页号 = 逻辑地址 / 页面长度 (取除法的整数部分)
- 页内偏移量 = 逻辑地址 % 页面长度(取除法的余数部分)
7. 基本地址变换机构
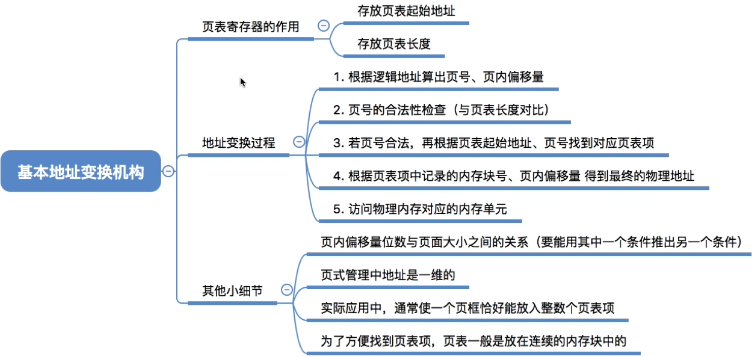
- 基本地址变换机构:用于实现逻辑地址到物理地址转换的一组硬件机构
7.1 页表寄存器
基本地址变换机构可以借助进程的页表将逻辑地址转换为物理地址
通常会在系统中设置一个页表寄存器(PTR),存放页表在内存中的起始地址F和页表长度M
进程未执行时,页表的始址和页表长度放在PCB(进程控制块)中,当进程被调度时,操作系统内核会把它们放到页表寄存器中
7.2 设页面大小为L,逻辑地址A到物理地址E的变换过程如下:
注意: 页面大小是2的整数幂
计算页号P和页内偏移量W
- 如果用十进制数手算,则 P = A / L, W = A % L
- 但是在计算机实际运行时,逻辑地址结构是固定不变的,因此计算机硬件可以更快地得到二进制表示的页号、页内偏移量
比较页号P和页表长度M,若 P ≥ M, 则产生越界中断,否则继续执行
- 注意:页号是从0开始的,而页表长度至少是1,因此P=M时也会越界
页表中页号P对应的 页表项地址 = 页表起始地址F + 页号P * 页表项长度 ,取出该页表项内容b,即为内存块号
- 注意区分页表项长度、 页表长度、页面大小的区别
- 页表长度:指的是这个页表中总共有几个页表项,即总共有几个页
- 页表项长度:指的是每个页表项占多大的存储空间
- 页面大小:指的是一个页面占多大的存储空间
计算 E = b * L + W,用得到的物理地址E去访存
- 如果内存块号、页面偏移量是用二进制表示的,那么把二者拼接起来就是最终的物理地址了
动手验证:
- 假设页面大小L = 1KB,最终要访问的内存块号b = 2,页内偏移量W = 1023
- ① 尝试用E = b * L + W计算目标物理地址
- ② 尝试把内存块号、页内偏移量用二进制表示,并把它们拼接起来得到物理地址
- 对比①、②的结果是否一致
例题:
- 在分页存储管理(页式管理)的系统中,只要确定了每个页面的大小,逻辑地址结构就确定了。因此,页式管理中地址是一维的
- 即,只要给出一个逻辑地址,系统就可以自动地算出页号、页内偏移量两个部分,并不需要显式地告诉系统这个逻辑地址中,页内偏移量占多少位
7.3 页表项大小

8. 具有快表的地址变换机构
- 具有快表的地址变换机构:是基本地址变换机构的改进版本

8.1 什么是快表(TLB)?
- 快表,又称联想寄存器(TLB, translation lookaside buffer),是一种访问速度比内存快很多的高速缓存(TLB不是内存!),用来存放最近访问的页表项的副本,可以加速地址变换的速度。与此对应,内存中的页表常称为慢表
- 引入快表后的地址变换过程:
- CPU给出逻辑地址,由某个硬件算得页号、页内偏移量,将页号与快表中的所有页号进行比较
- 如果找到匹配的页号,说明要访问的页表项在快表中有副本,则直接从中取出该页对应的内存块号,再将内存块号与页内偏移量拼接形成物理地址,最后,访问该物理地址对应的内存单元。因此,若快表命中,则访问某个逻辑地址仅需一次访存即可
- 如果没有找到匹配的页号,则需要访问内存中的页表,找到对应页表项,得到页面存放的内存块号,再将内存块号与页内偏移量拼接形成物理地址,最后,访问该物理地址对应的内存单元。因此,若快表未命中,则访问某个逻辑地址需要两次访存
- 注意:在找到页表项后,应同时将其存入快表,以便后面可能的再次访问。若快表己满,则必须按照一定的算法对旧的页表项进行替换
- 由于查询快表的速度比查询页表的速度快很多,因此只要快表命中,就可以节省很多时间
- 因为局部性原理,一般来说快表的命中率可以达到90%以上
- 例:某系统使用基本分页存储管理,并采用了具有快表的地址变换机构。访问一次快表耗时1us,访问一次内存耗100us。若快表的命中率为90%,那么访问一个逻辑地址的平均耗时是多少?
- (1 + 100) * 0.9 + (1 + 100 + 100) * 0.1 = 111 us
- 有的系统支持快表和慢表同时查找,如果是这样,平均耗时应该是:
- (1 + 100) * 0.9 + (100 + 100) * 0.1 = 110.9 us
- 若未采用快表机制,则访问一个逻辑地址需要:
- 100 + 100 = 200us
- 显然,引入快表机制后,访问一个逻辑地址的速度快多了
- 例:某系统使用基本分页存储管理,并采用了具有快表的地址变换机构。访问一次快表耗时1us,访问一次内存耗100us。若快表的命中率为90%,那么访问一个逻辑地址的平均耗时是多少?
8.2 局部性原理
- 时间局部性
- 如果执行了程序中的某条指令,那么不久后这条指令很有可能再次执行;如果某个数据被访问过,不久之后该数据很可能再次被访问(因为程序中存在大量的循环)
- 空间局部性
- 一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也很有可能被访问(因为很多数据在内存中都是连续存放的,并且程序的指令也是顺序地在内存中存放的)
- 上小节介绍的基本地址变换机构中,每次要访问一个逻辑地址,都需要查询内存中的页表。由于局部性原理,可能连续很多次查到的都是同一个页表项
9. 两级页表
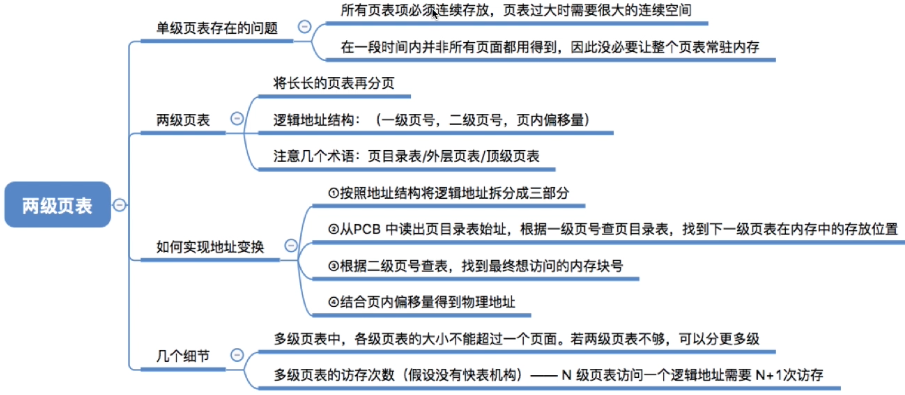
9.1 单级页表存在的问题
- 某计算机系统按字节寻址,支持 32
位的逻辑地址,采用分页存储管理,页面大小为4KB,页表项长度为 4B
- 4KB = 212B,因此页内地址要用12位表示,剩余 20 位表示页号
- 因此,该系统中用户进程最多有 220 页。相应的,一个进程的页表中,最多会有 220 = 1M =1,048,576 个页表项,所以一个页表最大需要 220 * 4B = 222B,共需要 222 / 212 = 210个页框存储该页表,需要专门给进程分配210 = 1024个连续的页框来存放它的页表
- 根据页号查询页表的方法:K 号页对应的 页表项存放位置 = 页表始址 + K * 4
- 要在所有的页表项都连续存放的基础上才能用这种方法找到页表项
- 根据局部性原理可知,很多时候,进程在一段时间内只需要访问某几个页面就可以正常运行了,因此没有必要让整个页表都常驻内存
- 问题一:页表必须连续存放,因此当页表很大时,需要占用很多个连续的页框
- 思考:我们是如何解决进程在内存中必须连续存储的问题?
- 将进程地址空间分页,并为其建立一张页表,记录各页面的存放位置
- 同样的思路也可用于解决“页表必须连续存放”的问题,把必须连续存放的页表再分页
- 可将长长的页表进行分组,使每个内存块刚好可以放入一个分组(比如上面的例子中,页面大小4KB,每个页表项4B,每个页面可存放1K个页表项,因此每1K个连续的页表项为一组,每组刚好占一个内存块,再将各组离散地放到各个内存块中)
- 另外,要为离散分配的页表再建立一张页表,称为页目录表(又称外层页表或顶层页表)
- 思考:我们是如何解决进程在内存中必须连续存储的问题?
- 问题二:没有必要让整个页表常驻内存,因为进程在一段时间内可能只需要访问某几个特定的页面
- 可以在需要访问页面时才把页面调入内存(虚拟存储技术), 可以在页表项中增加一个标志位,用于表示该页面是否已经调入内存
- 若想访问的页面不在内存中,则产生缺页中断(内中断/异常),然后将目标页面从外存调入内存
9.2 两级页表的原理、地址结构
- 如何实现地址变换
- 按照地址结构将逻辑地址拆分成三部分(一级页号、二级页号、页内偏移量)
- 从PCB 中读出页目录表始址,再根据一级页号查页目录表,找到下一级页表在内存中的存放位置
- 根据二级页号查二级页表,找到最终想访问的内存块号
- 结合页内偏移量得到物理地址
9.3 需要注意的几个细节
- 若分为两级页表后,页表依然很长,则可以采用更多级页表,一般来说各级页表的大小不能超过一个页面
- 例:某系统按字节编址,采用 40 位逻辑地址,页面大小为
4KB,页表项大小为
4B,假设采用纯页式存储,则要采用()级页表,页内偏移量为()位?
- 页面大小 = 4KB = 212B,按字节编址,因此页内偏移量为12位
- 页号 = 40 - 12 = 28 位
- 页面大小 = 212B,页表项大小 = 4B,则每个页面可存放 212 / 4 = 210个页表项
- 因此各级页表最多包含 210个页表项,需要10位二进制位才能映射到 210个页表项
- 因此每一级的页表对应页号应为10位,总共28位的页号至少要分为三级
- 如果只分为两级页表,则一级页号占 18 位,也就是说页目录表中最多可能有 218 个页表项,显然,一个页面是放不下这么多页表项的
- 例:某系统按字节编址,采用 40 位逻辑地址,页面大小为
4KB,页表项大小为
4B,假设采用纯页式存储,则要采用()级页表,页内偏移量为()位?
- 两级页表的访存次数分析(假设没有快表机构)
- 第一次访存:访问内存中的页目录表
- 第二次访存:访问内存中的二级页表
- 第三次访存:访问目标内存单元
10. 基本分段存储管理方式
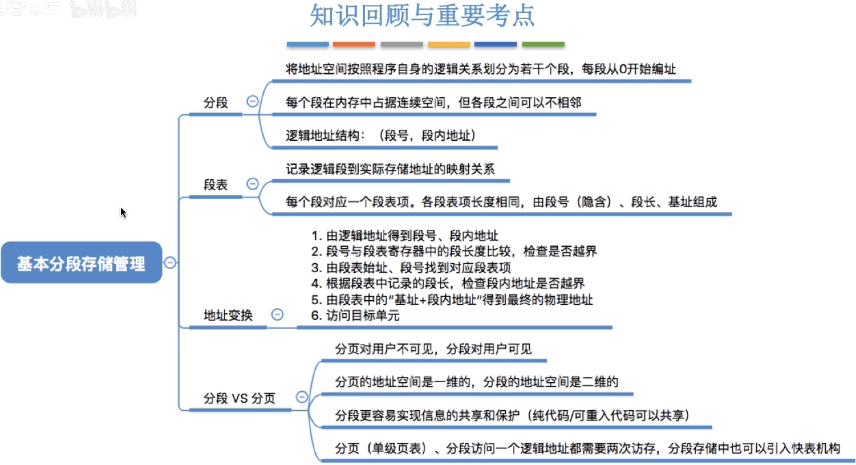
基本分段存储管理:与“分页”最大的区别就是 -- 离散分配时所分配地址空间的基本单位不同
10.1 分段
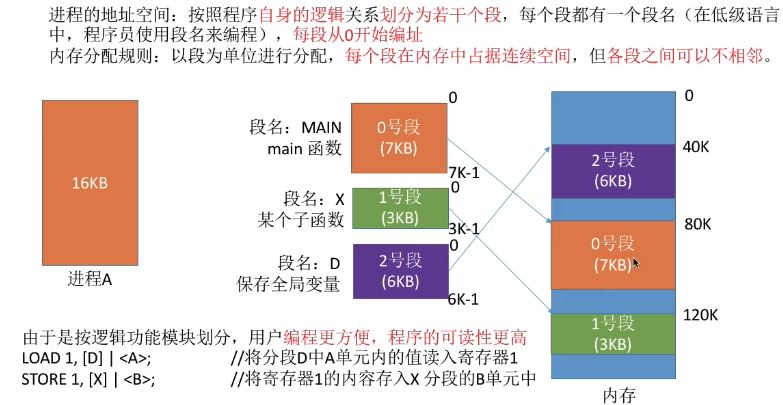
进程的地址空间:按照程序自身的逻辑关系划分为若干个段,每个段都有一个段名(在低级语言中,程序员使用段名来编程),每段从0开始编址
内存分配规则:以段为单位进行分配,每个段在内存中占据连续空间,但各段之间可以不相邻
- 分段系统的逻辑地址结构由段号(段名)和段内地址(段内偏移量)组成。如:
10.2 段表
- 程序分多个段,各段离散地装入内存,为了保证程序能正常运行,就必须能从物理内存中找到各个逻辑段的存放位置。为此,需为每个进程建立一张段映射表,简称“段表”
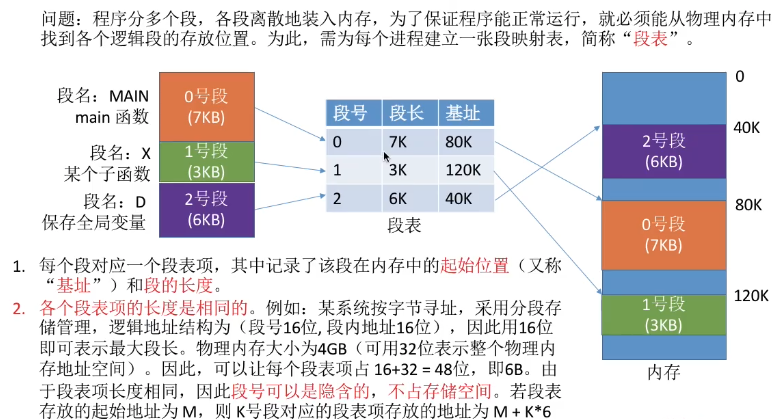
10.3 分段、分页管理的区别
页是信息的物理单位。分页的主要目的是为了实现离散分配,提高内存利用率。分页仅仅是系统管理上的需要,完全是系统行为,对用户是不可见的
段是信息的逻辑单位。分段的主要目的是更好地满足用户需求。一个段通常包含着一组属于一个逻辑模块的信息。分段对用户是可见的,用户编程时需要显式地给出段名
页的大小固定且由系统决定。段的长度却不固定,决定于用户编写的程序
分页的用户进程地址空间是一维的,程序员只需给出一个记忆符即可表示一个地址
分段的用户进程地址空间是二维的,程序员在标识一个地址时,既要给出段名,也要给出段内地址
分段比分页更容易实现信息的共享和保护
- 只需让各进程的段表项指向同一个段即可实现共享;页面不是按逻辑模块划分的,这就很难实现共享
- 不能被修改的代码称为纯代码或可重入代码(不属于临界资源),这样的代码是可以共享的。可修改的代码是不能共享的(比如,有一个代码段中有很多变量,各进程并发地同时访问可能造成数据不一致)
访问一个逻辑地址需要几次访存?
- 分页(单级页表):第一次访存 -- 查内存中的页表,第二次访存 -- 访问目标内存单元。总共两次访存
- 分段:第一次访存 -- 查内存中的段表,第二次访存 -- 访问目标内存单元。总共两次访存
- 与分页系统类似,分段系统中也可以引入快表机构,将近期访问过的段表项放到快表中,这样可以少一次访问,加快地址变换速度
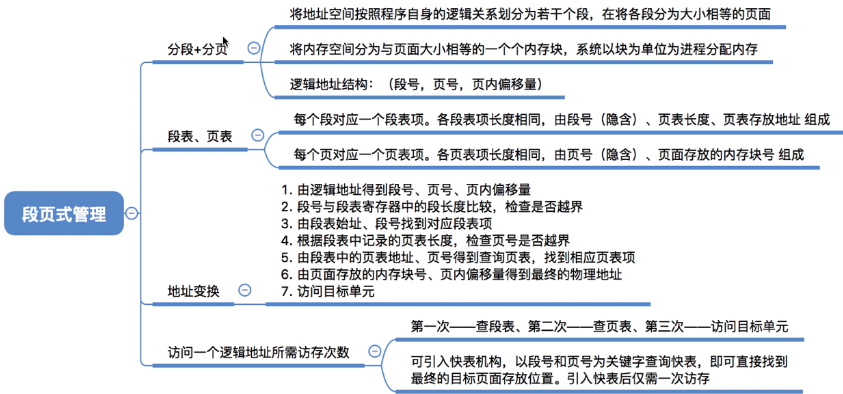
11. 段页式管理方式
11.1 分页、分段的优缺点分析
| 优点 | 缺点 | |
|---|---|---|
| 分页管理 | 内存空间利用率高,不会产生外部碎片,只会有少量的页内碎片 | 不方便按照逻辑模块实现信息的共享和保护 |
| 分段管理 | 很方便按照逻辑模块实现信息的共享和保护 | 如果段长过大,为其分配很大的连续空间会很不方便。另外,段式管理会产生外部碎片 |
- 分段管理中产生的外部碎片也可以用“紧凑”来解决,只是需要付出较大的时间代价
11.2 分段 + 分页 = 段页式管理
- 将进程按逻辑模块分段,再将各段分页(如每个页面4KB)
- 再将内存空间分为大小相同的内存块/页框/页帧/物理块
- 进程前将各页面分别装入各内存块中
11.3 段页式管理的逻辑地址结构
- 分段系统的逻辑地址结构由段号(段名)和段内地址(段内偏移量)组成。如:

- 段页式系统的逻辑地址结构由段号、页号、页内地址(页内偏移量)组成。如:
- 段号的位数决定了每个进程最多可以分几个段
- 页号位数决定了每个段最大有多少页
- 页内偏移量决定了页面大小、内存块大小是多少
- 在上述例子中,若系统是按字节寻址的,则
- 段号占16位,因此在该系统中,每个进程最多有216=64K个段
- 页号占4位,因此每个段最多有24=16页
- 页内偏移量占12位,因此每个页面每个内存块大小为212=4096=4KB
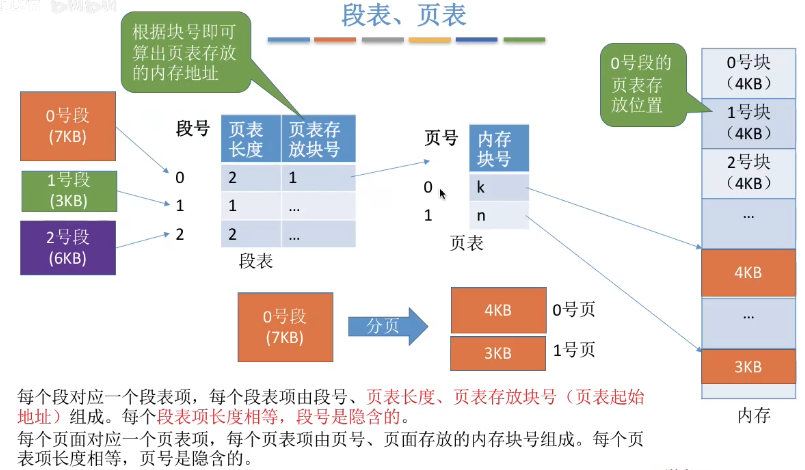
11.4 段表、页表
- 每个段对应一个段表项,每个段表项由段号、页表长度、页表存放块号(页表起始地址)组成。每个段表项长度相等,段号是隐含的。
- 每个页面对应一个页表项,每个页表项由页号、页面存放的内存块号组成。每个页表项长度相等,页号是隐含的。
11.5 段页式管理地址变换过程
根据逻辑地址得到段号、页号、页内偏移量
判断段号是否越界。若S≥M,则产生越界中断,否则继续执行
查询段表找到对应的段表项,段表项的存放地址为F+S*段表项长度
检查页号是否越界,若页号≥页表长度,则发生越界中断,否则继续执行
根据页表存放块号、页号查询页表找到对应页表项
根据内存块号页内偏移量得到最终的物理地址
访问目标内存单元