1. 初探强化学习
1. 强化学习简介
1.1 两种人工智能任务类型
- 预测型任务
- 根据数据预测所需输出(有监督学习)
- 生成数据实例(无监督学习)
- 决策型任务
- 在动态环境中采取行动(强化学习)
- 转变到新的状态
- 获得即时奖励
- 随着时间的推移最大化累计奖励 (Learning from interaction in a trial-and-error manner)
- 在动态环境中采取行动(强化学习)
1.2 强化学习定义
- 通过从交互中学习来实现目标的计算方法
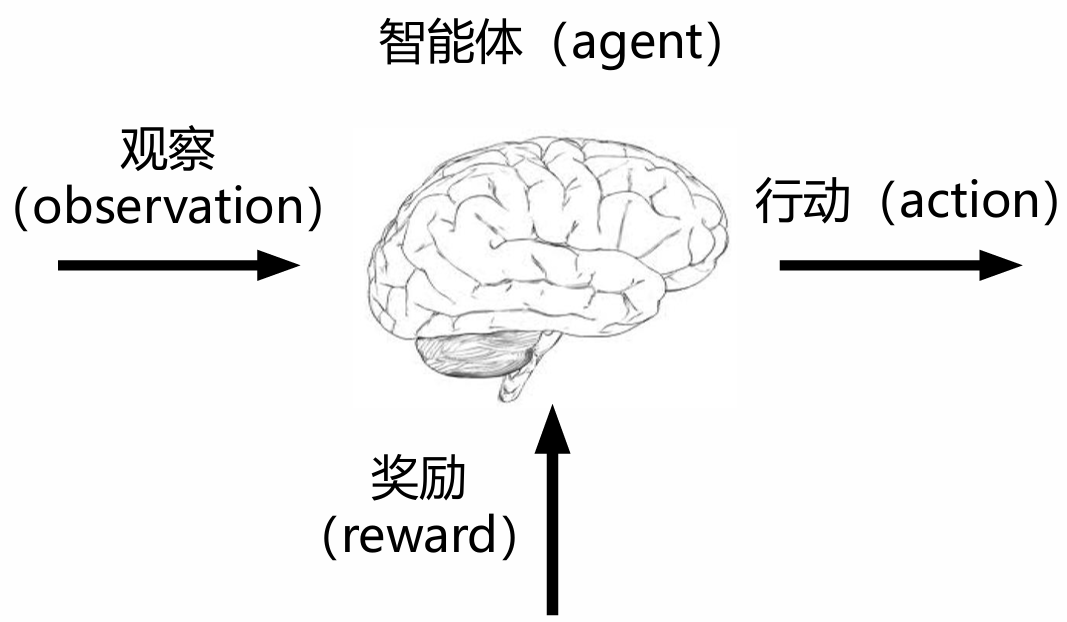
- 三个方面:
- 感知:在某种程度上感知环境的状态
- 行动:可以采取行动来影响状态或者达到目标
- 目标:随着时间推移最大化累积奖励
1.3 强化学习交互过程
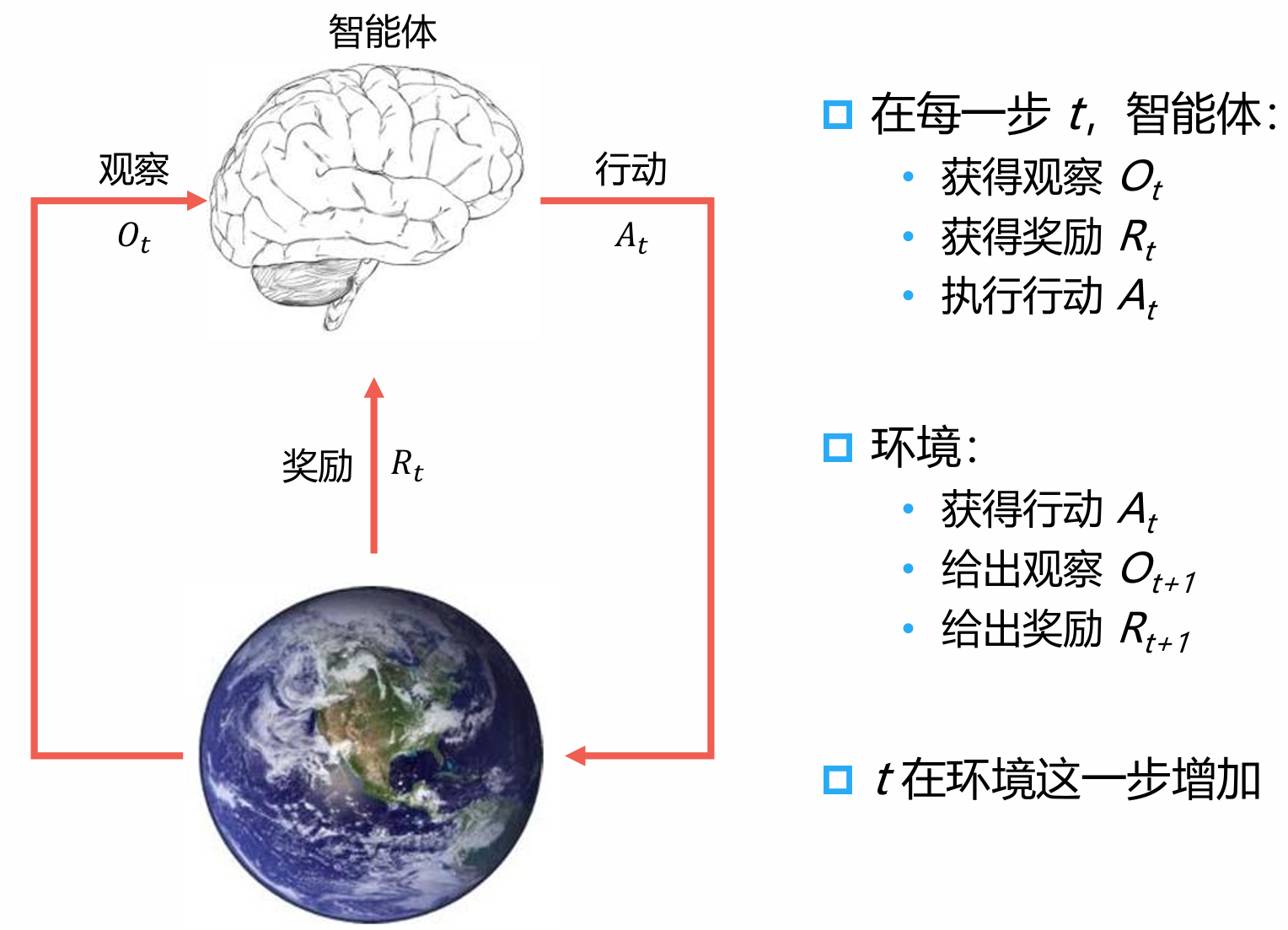
1.4 强化学习系统要素
- 历史(History)是观察、行动和奖励的序列
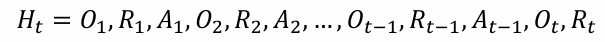
即,一直到时间t 为止的所有可观测变量
根据这个历史可以决定接下来会发生什么
- 智能体选择行动
- 环境选择观察和奖励
- 状态(state)是一种用于确定接下来会发生的事情(行动、观察、 奖励)的信息
- 状态是关于历史的函数St= 𝑓(𝐻𝑡)
- 策略(Policy)是学习智能体在特定时间的行为方式
- 是从状态到行动的映射
- 确定性策略(Deterministic Policy)
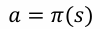
- 随机策略(Stochastic Policy)
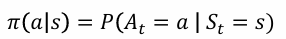
- 奖励(Reward)R(𝑠,𝑎)
- 一个定义强化学习目标的标量
- 能立即感知到什么是“好”的
- 价值函数(Value Function)
- 状态价值是一个标量,用于定义对于长期来说什么是 “好”的
- 价值函数是对于未来累积奖励的预测
- 用于评估在给定的策略下,状态的好坏
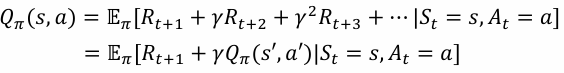
环境的模型(Model)用于模拟环境的行为
预测下一个状态(状态转移)
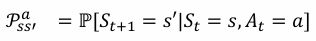
- 预测下一个(立即)奖励(奖励函数)
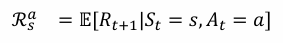
1.5 强化学习智能体分类
- 基于模型的强化学习
- 策略(和/或)价值函数
- 环境模型
- 比如:上述迷宫游戏,围棋等奖励
- 模型无关的强化学习
- 策略(和/或)价值函数
- 没有环境模型
- 比如:Atari游戏的通用策略
1.6 强化学习的方法分类
- 基于价值:知道什么是好的什么是坏的
- 没有策略(隐含)
- 价值函数
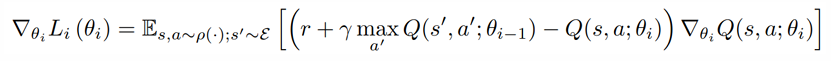
- 基于策略:知道怎么行动
- 策略
- 没有价值函数
- Actor-Critic:学生听老师的
- 策略
- 价值函数
1. 初探强化学习
http://binbo-zappy.github.io/2024/11/29/动手学强化学习/1-初探强化学习/