9.1 多智能体强化学习
基本概念
多智能体强化学习有四种常见的设定:
- Fully cooperative:各个agent的利益一致,获得的奖励相同,比如同一条生产流水线上的各个机器。
- Fully competitive:各个agent相互竞争,一方的收获是另一方的损失。
- Mixed Cooperative & competitive:各个agent之间即存在合作也存在竞争,比如moba游戏中多人一队,队伍之间相互对抗,队伍内部相互合作。
- Self-interested:利己主义,是指每个agent只想最大化自己收益,至于别人收益的高低它不在乎。
第\(i\)个智能体的Discounted return\(U_t^i\)定义为:
\(U_t^i = R_t^i + \gamma R_{t+1}^i + \gamma^2 R_{t+2}^i + \gamma^3 R_{t+3}^i + \ldots + \gamma^n R_n^i\)
每个agent都有自己的policy network\(\pi(a^i | s; \theta^i)\)。
第\(i\)个agent的state-value function\(V^i(s_t; \theta^1, \ldots, \theta^n)\)定义为:
\(V^i(s_t; \theta^1, \ldots, \theta^n) = E[U_t^i | S_t = s_t]\)
单智能体强化学习的目标是使\(J(\theta) = E_S(V(S, \theta))\)。
多智能体强化学习判断收敛的标准是纳什均衡,每个玩家都有自己的\(J^i(\theta^1, \theta^2, \ldots, \theta^n) = E_S(V^i(S, \theta^1, \theta^2, \ldots, \theta^n))\),
如果对于任意一个玩家来说,如果其他玩家选择的策略不变,那么不能通过改变当前策略来提高\(J^i\)值的话,就说明达到了nash均衡。
三种架构
三种架构分别为:
- Fully decentralized:完全去中心化:每个agent使用自己的观测和奖励来学习自己的策略。Agents do not communicate。
- Fully centralized:完全中心化:The agents send everything to the central controller. The controller makes decisions for all the agents。
- Centralized training with decentralized execution:A central controller is used during training. The controller is disabled after training.
- Fully decentralized 中每个agent单独训练自己的网络,它基于自己的策略网络采取动作,并观测动作发生后自己的状态和奖励,跟前面的单智能体强化学习一样。

- Fully centralized 由中心决定该做什么,中心有n个策略网络和价值网络,对应n个agents,它接收观测值来更新网络并决定动作。这样做的好处是中心知道所有的状态和价值,可以更好的训练网络和决定动作,坏处是速度会变慢。
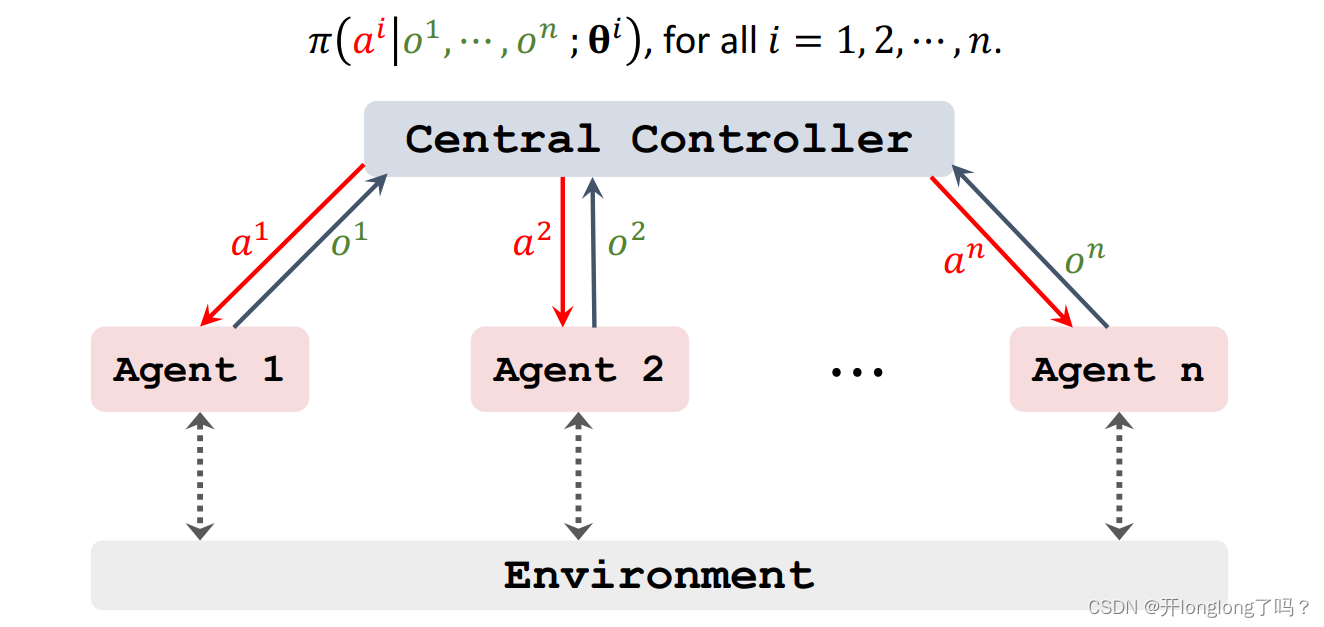
Centralized training with decentralized execution,每个agent独立持有自己的策略函数,中心持有n个价值函数,对应n个agent。训练过程是中心化的,中心知道所有的观测状态、动作、奖励;训练结果是去中心化的,每个agent已经训练好了自己的策略函数,中心的价值函数就没必要存在了。
如下图所示,每个agent基于自己的策略函数采取动作,然后相关信息传给中心。

如图所示,中心接收到信息后,训练并调用q函数,计算q值返回给各个agent。

