10. 集成学习
- 个体与集成
- 集成学习(ensemblelearning)通过构建并结合多个学习器来提升性能
- 集成个体应:好而不同
- 假设基分类器的错误率相互独立,则由Hoeffding不等式可得集成的错误率为:
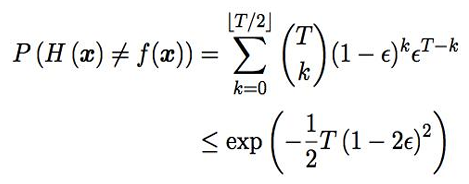
- 上式显示,在一定条件下,随着集成分类器数目的增加,集成的错误率将指数级下降,最终趋向于0
- 分析
- 上面的分析有一个关键假设:基学习器的误差相互独立
- 现实任务中,个体学习器是为解决同一个问题训练出来的,显然不可能互相独立
- 事实上,个体学习器的“准确性”和“多样性”本身就存在冲突
- 如何产生“好而不同”的个体学习器是集成学习研究的核心
- 集成学习大致可分为两大类
- Boosting
- 个体学习器存在强依赖关系
- 串行生成
- 每次调整训练数据的样本分布
- Boosting族算法最著名的代表是AdaBoost

- 基学习器的线性组合
- 达到了贝叶斯最优错误率,说明指数损失函数是分类任务原来0/1损失函数的一致替代函数。
- 数据分布的学习
- 重赋权法:在训练的每一轮中,根据样本分布为每个训练样本重新赋予一个权重。
- 重采样法:在训练的每一轮中,根据样本分布对训练集重新采样,再用重采样而得的样本集对基学习器进行训练。
- 重启动,避免训练过程过早停止
- 从偏差-方差的角度:降低偏差,可对泛化性能相当弱的学习器构造出很强的集成
- Bagging与随机森林
- 个体学习器不存在强依赖关系:欲得到泛化性能强的集成,集成中的个体学习器应尽可能相互独立,但“独立”在现实中无法做到,可以设法使基学习器尽可能具有较大的差异。例如产生若干个不同的子集,再从每个数据子集中训练出一个基学习器;
- 但如果每个子集完全不一样,则每个基学习器只用到一小部分数据训练,又无法保证个体学习器的性能。
- 并行化生成
- 自助采样法——Bagging

- 特点
- 时间复杂度低

- 时间复杂度低
- 自助采样法--自助法
- 评估方法
- 留出法
- 交叉验证法
- 留一法
- 留出法
- bagging实验
- 从偏差-方差的角度:降低方差,在不剪枝的决策树、神经网络等易受样本影响的学习器上效果更好
- 从偏差-方差的角度:降低方差,在不剪枝的决策树、神经网络等易受样本影响的学习器上效果更好
- 随机森林
- 随机森林(RandomForest,简称RF)是Bagging的一个扩展变种,以决策树为基础,进一步在决策树的训练过程中引入了随机属性选择。
- 采样的随机性:训练集的划分;
- 属性选择的随机性:在随机选择的k个属性集合中,依次选择最优属性进行划分,k为随机性的引入程度
- 随机森林的优点
- RF简单,容易实现,计算开销小;在很多现实任务中展现出强大的性能,被誉为代表集成学习水平的方法。
- RF中的基学习器的多样性不仅来自于样本的扰动,还来自属性的扰动,使得最终集成的泛化性能可以通过个体学习器之间的差异度增加而进一步提升。
- 随着个体学习器数目的增加,随机森林通常可以收敛到更低的泛化误差;训练效率常常优于其他Bagging方法。
- 结合策略
- 平均法
- 简单平均法
- 加权平均法
- 特点
- 简单平均法是加权平均法的特例
- 加权平均法在二十世纪五十年代被广泛使用
- 集成学习中的各种结合方法都可以看成是加权平均法的变种或特例
- 加权平均法可认为是集成学习研究的基本出发点
- 加权平均法未必一定优于简单平均法
- 投票法
- 绝对多数投票法
- 相对多数投票法
- 加权投票法
- 学习法
- Stacking是学习法的典型代表
- 从初始数据集训练出初级学习器,然后生成一个新数据集用于训练次级学习器,初级学习器的输出被当成样例输入特征,而初级样本的标记仍当做样例的标记。
- 多响应线性回归(MLR)作为次级学习器的学习算法,效果较好
- K折交叉验证/留一法,学习T个初级学习器
- Stacking是学习法的典型代表
- 平均法
- 误差-分歧分解
- 分歧项代表了个体学习器在样本回上的不一致性,即在一定程度上反映了个体学习器的多样性,
- 个体和集成
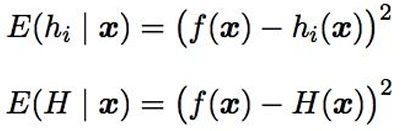
- 个体和集成
- 个体学习器准确率越高,多样性越大,则集成越好。
- 多样性度量(diversitymeasure)用于度量集成中个体学习器的多样性
- 对于二分类问题,分类器ℎ�与ℎ�的预测结果联立表(contingencytable)为
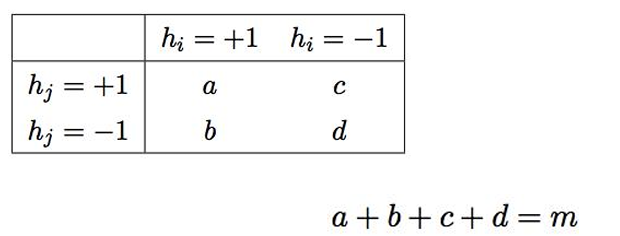
- 常见的多样性度量

- Q统计量
- K统计量
- 分歧项代表了个体学习器在样本回上的不一致性,即在一定程度上反映了个体学习器的多样性,
- 多样性增强
- 常见的增强个体学习器多样性的方法
- 数据样本扰动
- 输入属性扰动
- 输出表示扰动
- 算法参数扰动
- 基学习法一般都有参数需要设置,例如神经网络的隐层神经元数,初始连接权值,通过随机设置不同的参数,往往可产生差别较大的个体学习器;
- 负相关法:显式的通过正则化项来强制个体神经网络使用不同的参数;
- 不同的多样性增强机制同时使用:例如随机森林中同时使用数据样本扰动和输入属性扰动
- 数据样本扰动通常是基于采样法
- Bagging中的自助采样法
- Adaboost中的序列采样
- 数据样本扰动对“不稳定基学习器”很有效
- 对数据样本扰动敏感的基学习器(不稳定基学习器)
- 决策树
- 神经网络等
- 对数据样本扰动不敏感的基学习器(稳定基学习器)
- 线性学习器,支持向量机,朴素贝叶斯,k近邻等
- 输出表示扰动
- 将输出表示进行操控以增强多样性;
- 翻转法(FlippingOutput):随机改变一些训练样本的标记;
- 输出调剂法(OutputSmearing):对输出表示进行转换,例如将分类输出转化为回归输出后构建个体分类器;
- ECOC法:利用纠错输出码将多类任务拆解为一系列二分类任务来训练基学习器;
- 常见的增强个体学习器多样性的方法






10. 集成学习
http://binbo-zappy.github.io/2024/12/07/PR-ML/10-集成学习/