10. C++编译链接模型精要
第10章 C++编译链接模型精要
C++从C语言继承了一种古老的编译模型,引发了其他语言中根本不存在的一些编译方面的问题(比如“一次定义原则(ODR)”)。理解这些问题有助于在实际开发中规避各种古怪的错误。
C++语言的三大约束是:与C兼容、零开销(zero overhead)原则、值语义。下面谈谈第一点“与C兼容”。
“与C兼容”的含义很丰富,不仅仅是兼容C的语法,更重要的是兼容C语言的编译模型与运行模型,也就是说能直接使用C语言的头文件和库。比如对于connect(2)这个系统函数,它的头文件和原型如下:
1 | |
C++的基本类型的长度和表示(representation)必须和C语言一样(int、指针等),准确地说是和编译系统库的C语言编译器保持一致。C++编译器必须能理解头文件sys/socket.h中struct sockaddr的定义,生成与C编译器完全相同的layout(包括采用相同的对齐算法),并且遵循C语言的函数调用约定(参数传递、返回值传递、栈管理等等),才能直接调用这个C语言库函数。
现代操作系统暴露出的原生接口往往是C语言描述的,Windows的原生API接口是Windows.h头文件,POSIX是一堆C语言头文件。C++兼容C,从而能在编译的时候直接使用这些头文件,并链接到相应的库上。并在运行的时候直接调用C语言的函数库,这省了一道中间层的手续,可算作是C++高效的原因之一。
图10-1表明了Linux上编译个C++程序的典型过程。其中最耗时间的是cc1plus这一步,在一台正在编译C++项目的机器上运行top(1),排在首位的往往就是这个进程。
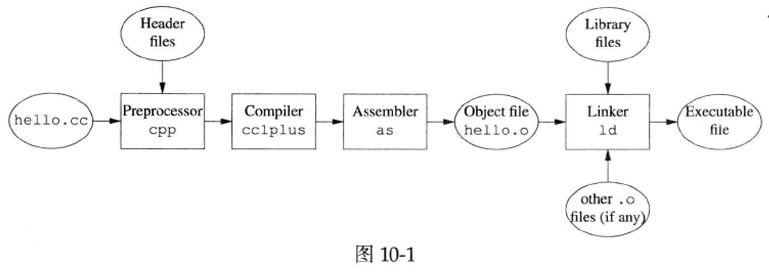
值得指出的是,图10-1中各个阶段的界线并不是铁定的。通常cpp和cclplus会合并成一个进程;而cc1plus和as之间既可以以临时文件(*.s)为中介,也可以以管道(pipe)为中介;对于单一源文件的小程序,往往不必生成.o文件。另外,linker还有一个名字叫做link
editor。
在不同的语境下,“编译”一词有不同的含义。如果笼统地说把.cc文件“编译”为可执行文件,那么指的是preprocessor/compiler/assembler/linker这四个步骤。如果区分“编译”和“链接”,那么“编译”通常指的是从源文件生成目标文件这几步(即g++-c)。如果进一步区分预处理、编译(代码转换)、汇编,那么编译器实际看到的是预处理器完成头文件替换和宏展开之后的源代码。
C++至今(包括C++11)没有模块机制,不能像其他现代编程语言那样用import或using来引入当前源文件用到的库(含其他package/module里的函数或类),而必须用include头文件的方式来机械地将库的接口声明以文本替换的方式载入,再重新parse一遍。这么做一方面让编译效率奇低,编译器动辄要parse几万行预处理之后的源码,哪怕源文件只有几百行;另一方面,也留下了巨大的隐患。部分原因是头文件包含具有传递性,引入不必要的依赖;另一个原因是头文件是在编译时使用,动态库文件是在运行时使用,二者的时间差可能带来不匹配,导致二进制兼容性方面的问题。C++的设计者Bjarne Stroustrup自己很清楚这一点,但这是在“与C兼容”的大前提下不得不做出的妥协。
比如有一个简单的小程序,只用了printf(3),却不得不包含stdio.h,把其他不相关的函数、struct定义、宏、typedef、全局变量等等也统统引入到当前命名空间。在预处理的时候会读取近20个头文件,预处理之后供编译器parse的源码有近千行(这还算是短的)。
1 | |
gcc -E hello.cc | wc 预处理之后有942行。
strace -f -e open cpp hello.cc -o /dev/null 2>&1 | grep -v ENOENT | awk '{print $3}'
读者若有兴趣,可将其中的stdio.h替换为C++标准库的头文件complex,看看预处理之后的源代码有多少行,额外包含了哪些头文件。(在我的机器上测试,预处理之后有21879行,包含了近150个头文件,包括<string>、<sstream>等大块头。)
值得一提的是,为了兼容C语言,C++付出了很大的代价。例如要兼容C语言的隐式类型转换规则(例如整数类型提升),这让C++的函数重载决议规则变得无比复杂。另外class定义式后面那个分号也不晓得谋杀了多少初学者的时间,这是为了与C struct语法兼容,因为C允许在函数返回类型处定义新struct类型,因此分号是必需的。Bjarne Stroustrup自己也说“我又不是不懂如何设计出比C++更漂亮的语言”。(由于C语言没有函数重载,也就不存在重载决议,所以隐式类型转换的危害没有体现在这一方面。)
1. C语言的编译模型及其成因
要想了解C语言的编译模型的成因,我们需要略微回顾一下Unix的早期历史。
1969年Ken Thompson用汇编语言在一台闲置的PDP-7小型机上写出了Unix的史前版本。值得一提的是,PDP-7的字长是18-bit,只能按字(word)寻址,不支持今日常见的按8-bit字节寻址。假如C语言诞生在PDP-7上,计算机软硬件的发展史恐怕要改写。
1970年5月,Ken Thompson和Dennis Ritchie所在的贝尔实验室下订单购买了一台PDP-11小型机,这是1970年1月刚刚上市的新机型。PDP-11的字长是16-bit,可以按8-bit字节寻址,这可谓一举奠定了今后C语言及硬件的发展道路。这台机器的主机(处理器和内存)当年夏天就到货了,但是硬盘直到1970年12月才到货。
1971年,Ken Thompson把原来运行在PDP-7上的Unix用PDP-11汇编靠人力重写了一遍,运行在这台PDP-11/20机器上。这台机器一共只有24KiB内存,其中16KiB运行操作系统,8KiB运行用户代码;硬盘一共只有512KiB,文件大小限制为64KiB。然后实现了一个文本处理器,用于排版贝尔实验室的专利申请,这是购买这台计算机的正经用途。
1972年是C语言历史上最为关键的一年,这一年C语言加入了预处理,具备编写大型程序的能力。到了1973年初,C语基本定型,主要新特性是支持结构体。此时C语言的编译模型已经基本定型,即分为预处理、编译、汇编、链接这四个步骤,沿用至今。
1973年是Unix历史上关键的一年,这一年夏天,二人把Unix的内核用C语言重写了一遍,完成了用高级语言编写操作系统的伟大创举。(Thompson在1972年就尝试过用C重写Unix内核,但是当时的C语言不支持结构体,因此他放弃了。)
随后,1974年,Dennis Ritchie和Ken Thompson发表了经典论文《The UNIX Time-Sharing System》。除了没有函数原型声明外,1974年的C代码读起来跟现在的C程序基本无区别。
1.1 为什么C语言需要预处理
了解了C语言的诞生背景,我们可以归纳PDP-11上的第一代C编译器的硬性约束:内存地址空间只有16-bit,程序和数据必须挤在这狭小的64KiB空间里,可谓捉襟见肘。注意,本节提到的C语言甚至早于1978年的K&R C,是20世纪70年代最初几年的原始C语言。
编译器没办法在内存里完整地表示单个源文件的抽象语法树,更不可能把整个程序(由多个源文件组成)放到内存中,以完成交叉引用(不同源文件的函数之间相互调用,使用外部变量等等)。由于内存限制,编译器必须要能分别编译多个源文件,生成多个目标文件,再设法把这些目标文件组合(链接)为一个可执行文件。
在今天看来,C语言这种支持把一个大程序分成多个源文件的“功能”几乎是顺理成章的。但是在当时而言,并不是每个语言都有意地做到这一点。我们以同一时期(1968-1974)Niklaus Wirth设计的Pascal语言为对照。Pascal语言可以定义函数和结构体,也支持指针,语法也比当时的C语言更优美。但它长期没有官方规定的多源文件模块化机制,它要求每个程序(program)必须位于同一个源文件,这其实大大限制了它在系统编程方面的用途。如果Pascal一早就克服这些缺点,“那么我们今天可能要把begin和end直接映射到键盘上。”
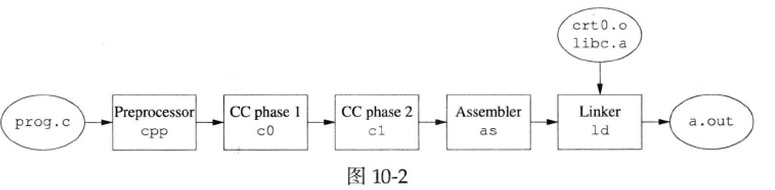
或许是受内存限制,一个可执行程序不能太大,Dennis Ritchie编写的PDP-11 C编译器不是一个可执行文件,而是7个可执行文件:cc、cpp、as、ld、co、c1、c2。其中cc是个driver,用于调用另外几个程序。cpp是预处理器(Unix V7从co分离出来),当时叫做compiler control line expander。co、c1、c2是C编译器的三个阶段,co的作用是把源程序编译为两个中间文件:c1把中间文件编译为汇编源代码;c2是可选的,用于对生成汇编代码做窥孔优化。as是汇编器,把汇编代码转换为目标文件。ld是链接器,把目标文件和库文件链接成可执行文件。编译流程见图10-2。不用cc,手工编译一个简单程序prog.c的过程如下:
1 | |
为了能在尽量减少内存使用的情况下实现分离编译,C语言采用了“隐式函数声明(implicit declaration of function)”的做法。代码在使用前文未定义的函数时,编译器不需要也不检查函数原型:既不检查参数个数,也不检查参数类型与返回值类型。编译器认为未声明的函数都返回int,并且能接受任意个数的int型参数。而且早期的C语言甚至不严格区分指针和int,而是认为二者可以相互赋值转换。在C++程 序员看来,这是毫无安全保障的做法,但是C语言就是如此地相信程序员。
其实,有了隐式函数声明,我们已经能分别编译多个源文件,然后把它们链接为一个大的可执行文件(此处指的是编译出来有几十KB的程序)。那么为什么还需要头文件和预处理呢?
根据Eric S.Raymond在《The Art of Unix Programming》第17.1.1节30引用Steve Johnson的话,最早的Unix是把内核数据结构(例如struct dirent)打印在手册上,然后每个程序自己在代码中定义struct。.例如UniⅸV5的1s(1)源码31中就自行定义了表示目录的结构体。有了预处理和头文件,这些公共信息就可以做成头文件放到/usr/include,然后程序包含用到的头文件即可。减少无谓错误,提高代码的可移植性。
最早的预处理只有两项功能:#include和#define。#include完成文件内容替换,#define只支持定义宏常量,不支持定义宏函数。早期的头文件里只放三样东西:struct定义,外部变量32的声明,宏常量。这样可以减少各个源文件里的重复代码。到目前为止,头文件的预处理的作用都还是正面的。
1.2 C语言的编译模型
由于不能将整个源文件的语法树保存在内存中,C语言其实是按“单遍编译”来设计的。所谓单遍编译,指的是从头到尾扫描一遍源码,一边解析代码,一边即刻生成目标代码。在单遍编译时,编译器只能看到目前(当前语句/符号之前)已经解析过的代码,看不到之后的代码,而且过眼即忘。这意味着
- C语言要求结构体必预先定义,才能访问其成员,否则编译器不知道结构体成员的类型和偏移量,就无法立刻生成目标代码。
- 局部变量也必须先定义再使用,因为如果把定义放到后面,编译器在第一次看到一个局部变量时并不知道它的类型和在stack中的位置,也就无法立刻生成代码,只能报错退出。
- 为了方便编译器分配stack空间,C语言要求局部变量只能在语句块的开始处定义。
- 对于外部变量,编译器只需要知道它的类型和名字,不需要知道它的地址,因此需要先声明后使用。在生成的目标代码中,外部变量的地址是个空白,留给链接器去填上。
- 当编译器看到一个函数调用时,按隐式函数声明规则,编译器可以立刻生成调用函数的汇编代码(函数参数入栈、调用、获取返回值),这里唯一尚不能确定的是函数的实际地址,编译器可以留下一个空白给链接器去填。
对C编译器来说,只需要记住struct的成员和偏移,知道外部变量的类型,就足以一边解析源代码,一边生成目标代码。因此早期的头文件和预处理恰好满足了编译器的需求。外部符号(函数或变量)的决议可以留给链接器去做。
从上面的编译过程可以发现,C编译器可以做得很小,只使用很少的内存。据我观察,Unix V5的C编译器甚至没有使用动态分配内存,而是用一些全局的栈和数组来帮助处理复杂表达式和语句嵌套,整个编译器的内存消耗是固定的。(我推测C语言不支持在函数内部嵌套定义函数也是受此影响,因为这样一来意味着必须用递归才能解析函数体,编译器的内存消耗就不是一个定值。)
受“不能嵌套”的影响,整个C语言的命名空间是平坦的,函数和struct都处于全局命名空间。这其实给C程序员带来了不少麻烦,因为每个库都要设法避免自己的函数和struct与其他库冲突。早期C语言甚至不允许在不同struct中使用相同的成员名称,因此我们看到一些struct的名字有前缀,例如struct timeval的成员是tv_sec和tv_usec,struct sockaddr_in的成员是sin_family、sin_port、sin_addr。
讲清楚了C语言的编译模型,我们再来看看它对C++的影响(和伤害)。
2. C++的编译模型
由于要保持与C兼容,原本很多在C语言中顺理成章或者危害不大的东西继承到了C++里就成了大祸害。
2.1 单遍编译
C++也继承了单遍编译。在单遍编译时,编译器只能根据自己前看到的代码做出决策,读到后面的代码也不会影响前面做出的决定。这特别影响了名字查找(name lookup)和函数重载决议。
先说名字查找,C++中的名字包括类型名、函数名、变量名、typedef名、template名等等。比如对下面这行代码:
1 | |
如果不知道Foo、T、a这三个名字分别代表什么,编译器就无法进行语法分析。根据之前出现的代码不同,上面这行语句至少有三种可能性:
- Foo是个template<typename T> class Foo;,T是type,那么这句话以T为模板类型参数类型具现化了Foo<T>类型,并定义了变量a。
- Foo是个template<int T> class Foo;,T是const int变量,那么这句话以T为非类型模板参数具现化了Foo<T>类型,并定义了变量a。
- Foo、T、a都是int,这句话是个没啥用的表达式语句。
别忘了operator<()是可以重载的,这句简单代码还可以表达别的意思。另外,一个经典的例子是AA BB(CC);,这句话既可以声明函数,也可以定义变量。
C++只能通过解析源码来了解名字的含义,不能像其他语言那样通过直接读取目标代码中的元数据来获得所需信息(函数原型、class类型定义等等)。这意味着要想准确理解一行C++代码的含义,我们需要通读这行代码之前的所有代码,并理解每个符号(包括操作符)的定义。而头文件的存在使得肉眼观察几乎是不可能的。完全有可能出现一种情况:某人不经意改变了头文件,或者仅仅是改变了源文件中头文件的包含顺序,就改变了代码的含义,破坏了代码的功能。这时能造成编译错误已经是谢天谢地了。
C++编译器的符号表至少要保存自前已看到的每个名字的含义,包括class的成员定义、已声明的变量、已知的函数原型等,才能正确解析源代码。这还没有考虑template,编译template的难度超乎想象。编译器还要正确处理作用域嵌套引发的名学的含义变化:内层作用域中的名字有可能遮住外层作用域中的名字。有些其他语言会对此发出警告,对此我建议用g++的-Wshadow选项来编译代码。(插一句题外话:muduo的代码都是-Wall -Wextra -Werror -Wconversion -Wshadow编译的。)
再说函数重载决议,当C++编译器读到一个函数调用语句时,它必须(也只能)从自前已看到的同名函数中选出最佳函数。哪怕后面的代码中出现了更合适的匹配,也不能影响当前的决定。这意味着如果我们交换两个namespace级的函数定义在源代码中的位置,那么有可能改变程序的行为。
比如对于如下一段代码:
1 | |
如果有人在重构的时候把void bar()的定义挪到void foo(char)之后,程序的输出就不一样了。
这个例子充分说明实现C++重构工具的难度:重构器对代码的理解必须达到编译器的水准,才能在修改代码时不改变原意。函数的参数可以是个复杂表达式,重构器必须能正确解析表达式的类型才能完成重载决议。比如foo(str[e])应该调用哪个foo跟string的类型有关,而str可能是个std::string,这就要求重构器能正确理解template并具现化之。C++至今没有像样的重构工具,恐怕正是这个原因。
C++编译器必须在内存中保存函数级的语法树,才能正确实施返回值优化(RVO),否则遇到return语句的时候编译器无法判断被返回的这个对象是不是那个可以被优化的named object。
其实由于C++新增了不少语言特性,C++编译器并不能真正做到像C那样的过眼即忘的单遍编译。但是C++必须兼容C的语义,因此编译器不得不装得好像是单遍编译(准确地说是单遍parse)一样,哪怕它内部是multiple pass的。
2.2 前向声明
几乎每份C++编码规范都会建议尽量使用前向声明来减少编译期依赖,这里我用“单向编译”来解释一下这为什么是可行的,很多时候甚至是必需的。
如果代码里调用了函数foo(),C++编译器parse此处函数调用时,需要生成函数调用的目标代码。为了完成语法检查并生成调用函数的目标代码,编译器需要知道函数的参数个数和类型以及函数的返回值类型,它并不需要知道函数体的实现(除非要做inline展开)。因此我们通常把函数原型放到头文件里,这样每个包含了此头文件的源文件都可以使用这个函数。这是每个C/C++程序员都明白的事情。
当然,光有函数原型是不够的,程序其中某一个源文件应该定义这个函数,否则会造成链接错误(未定义的符号)。这个定义foo()函数的源文件通常也会包含foo()的头文件。但是,假设在定义foo()函数时把参数类型写错了,会出现什么情况?
1 | |
编译foo.cc会有错吗?不会,因为编译器会认为foo有两个重载。但是链接整个程序会报错:找不到void
foo(int)的定义。你有没有遇到过类似的问题?这是C++的一种典型缺陷,即一样东西区分声明和定义,代码放到不同的文件中,这就有出现不一致的可能性。C/C++里很多稀奇古怪的错误就源自于此,比如[ExpC]举的一个经典例子:在一个源文件里声明extern char *name,在另一个源文件里却定义成char name["ShuoChen"]。
对于函数的原型声明和函数体定义而言,这种不一致表现在参数列表和返回类型上,编译器通常能查出参数列表不同,但不一定能查出返回类型不同。也可能参数类型相同,但是顺序调换了。例如原型声明为draw(int height, int width),定义的时候写成draw(int width, int height),编译器无法查出此类错误。
其他语言似乎没有这个问题。例如我们不需要在Java里使用函数原型声明,一个成员函数的参数列表只需要在代码里出现一次,不存在不一致的可能。Java编译器也不受“单遍编译”的约束,调整成员函数的顺序不会影响代码语义。Java也没有过时的头文件包含机制,而是有一套基于package的模块化机制,陷阱少得多。
如果要写一个库给别人用,那么通常要把接口函数的原型声明放到头文件里。但是在写库的内部实现的时候,如果没有出现函数相互调用的情况,那么我们可以适当组织函数定义的顺序,让基础函数出现在代码的前面,这样就不必前向声明函数原型了。
函数原型声明可以看作是对函数的前向声明(forward declaration),除此之外我们还常常用到class的前向声明。
有些时候class的前向声明是必需的,例如第10章出现的Child和Parent class相互指涉的情况。有些时候class的完整定义是必需的,例如要访问class的成员,或者要知道class的大小以便分配空间。其他时候,有class的前向声明就足够了,编译器只需要知道有这么个名字的class。
对于class Foo,以下几种使用不需要看见其完整定义:
- 定义或声明Foo*和Foo&,包括用于函数参数、返回类型、局部变量、类成员变量等等。这是因为C++的内存模型是flat的,Foo的定义无法改变Foo的指针或引用的含义。
- 声明一个以Foo为参数或返回类型的函数,如Foo bar()或void bar(Foo f),但是,如果代码重调用这个函数就需要知道Foo的定义,因为编译器要使用Foo的拷贝构造函数和析构函数,因此至少要看到它们的声明(虽然构造函数没有参数,但是有可能位于private区)。
muduo代码中大量使用前向声明来减少include,并且避免把内部class的定义暴露给用户代码。
[CCS]第30条规定不能重载&&、||、,(逗号)这三个操作符,Google的C++编程规范补充规定不能重载一元operator&(取址操作符),因为一旦重载operator&,这个class就不能用前向声明了。例如:
1 | |
代码的行为跟是否include Foo的完整定义有关,等于埋了“定时炸弹”。
3. C++链接(linking)
链接(linking)这个话题可以单独写一本书[LLL],这本书讲“C++链接”的有第4.4节“静态链接/C++相关问题”和第9.4节“C++与动态链接”等章节。
本节重点介绍与C++日常开发相关的链接方面的问题,先以手工编制一本书的目录和交叉索引为例,介绍链接器的基本工作原理。假设一个作者写完了十几个章节,你的任务是把这些章节编辑为一本书。每个章节的篇幅不等,从30页到80页都有,都已经分别排好版打印出来。(已经从源文件编译成了目标文件。)
章节之间有交叉引用,即正文里会出现“请参考XXX页的第YYY节”等样式。作者在撰写每个章节的时候并不知道当前文字的章节号,当然也不知道当前文学将来会出现在哪一页上。因为他可以随时调整章节顺序、增减文字内容,这些举动会影响最终的章节编号和页码。为了引用其他章节的内容,作者会在文学中放anchor(或者label),给需要被引用的文字命名。比方说本章“C++编译链接模型精要”的名字是ch:cppCompilation。(这就好比给全局函数或全局变量起了一个独一无二的名字。)在引用其他章节的编号或页码时,作者在正文中留下一个适当的空白,并注明这里应该填上的某个anchor的页码或章节编号(\(\LaTeX\)是)。
现在你拿到了这十几沓打印的文稿,怎么把它们编辑成一本书呢?你可能会想到下面这两个步骤:先编排页码和章节编号,再解决交叉引用。
第一步:
1a. 把这些文稿按章的先后顺序叠好,这样就可以统一编制正文页码。 1b. 在编制页码的同时,章节号也可以一并确定下来。
在进行1a和1b这个步骤时,你可以同时顺序记录两张纸:
- 一张纸记录每个章节的起始页码和结束页码。
- 另一张纸记录每个anchor的页码。
- 章节的编号、标题和它出现的页码,用于编制目录。
- 遇到anchor时,记下它的名字和出现的页码、章节号,用于解决交叉引用。
如果按上面的办法来操作,解决交叉引用就不难了。
第二步:
- 再从头翻一遍书稿,遇到空白的交叉引用,就到anchor索引表里查出它的页码和章节编号,填上空白。
至此,如果一切顺利的话,书籍编辑任务完成。请读者思考,为什么书的正文页码用阿拉伯数字,而前言和目录的页码通常是罗马数字?如果整本书从头到尾连续编排页码,手工处理会遇到什么困难?
在这项工作中最容易出现以下两种意外情况,也正是最常见的两种链接错误:
- 正文中交叉引用找不到对应的anchor,空白填不上咋办?
- 某个anchor多次定义,该选哪一个填到交叉引用的空白处呢?
上面描述的办法要至少翻两遍全文,有没有办法从头到尾只翻一遍书稿就完成交叉引用呢?如果作者在写书的时候只从前面的章节引用后面的章节,那么是可以做到这一点的。我们在编排页码和章节号的时候顺便阅读全文,遇到新的交叉引用空白就记到一张纸上。这张纸记录交叉引用的名字和空白出现的页码。我们知道后面肯定能退到对应的anchor。在遇到一个anchor时,去那张纸上看看有没有交叉引用用到它,如果有,就回翻到空白的页码,把空白填上,回头再继续编制页码和章节号。这样一遍扫下来,章节编号、页码、交叉引用就全部搞定了。
这正是传统one-pass链接器的工作方式,在使用这种链接器的时候要注意参数顺序,越基础的库越放到后面。如果程序用到了多个library,这些library之间有依赖(假设不存在循环依赖),那么链接器的参数顺序应该是依赖图的拓扑排序。这样保证每个未决符号都可以在后面出现的库中找到。比如A、B两个彼此独立的库同时依赖C库,那么链接的顺序是ABC或BAC。
为什么这个规定不是反过来,先列出基础库,再列出应用库呢?原因是前一种做法的内存消耗要小得多。如果先处理基础库,链接器不知道库中哪些符号会被后面的代码用到,因此只能每一个都记住,链接器的内存消耗跟所有库的大小之和成正比。反过来,如果先处理应用库,那么只需要记住目前尚未查到定义的符号就行了。链接器的内存消耗跟程序中外部符号的多少成正比(而且一旦填上空白,就可以删掉它)。
以上简要介绍了C语言的链接模型,C++与之相比主要增加了两项内容:
- 函数重载,需要类型安全的链接,即name mangling。
- Vague linkage,即同一个符号有多份互不冲突的定义。
Name mangling的事情一般不需要程序员操心,只要掌握extern"C"的用法,能和C程序库interoperate就行。何况现在一般的C语言库的头文件都会适当使用extern"C",便之也能用于C++程序。
C语言通常一个符号在程序中只能有一处定义,否则就会造成重复定义。C++则不同,编译器在处理单个源文件的时候并不知道某些符号是否应该在本编译单元定义。为了保险起见,只能每个目标文件生成一份“弱定义”,而依赖链接器去选择一份作为最终的定义,这就是vague linkage。不这么做的话就会出现未定义的符号错误,因为链接器通常不会聪明到反过来调用编译器去生成未定义的符号。为了让这种机制能正确运作,C++要求代码满足一次定义原则(ODR),否则代码的行为是随机的,视linker心情好坏而定。
以下分别简要谈谈这两方面对编程的影响。
3.1 函数重载
众所周知,为了实现函数重载,C++编译器普遍采用名字改编(name mangling)的办法,为每个重载函数生成独一无二的名字,这样在链接的时候就能找到正确的重载版本。比如foo.cc里定义了两个foo()重载函数。
1 | |
g++ -c foo.cc
nm foo.o
c++filt _Z3foob _Z3fooi
注意普通non-template函数的mangled name不包含返回类型。记得吗,返回类型不参与函数重载。
这其实有一个小小的隐患,也是“C++典型缺陷”的一个体现。如果一个源文件用到了重载函数,但它看到的函数原型声明的返回类型是错的(违反了ODR),链接器无法捕捉这样的错误。
1 | |
g++ -c main.cc
nm main.o
对于内置类型,这应该不会造成实际的影响。但是如果返回类型是class,那么就天晓得会发生什么了。
3.2 inline函数
inline函数的方方面面见[EC3]第30条。由于inline函数的关系,C++源代码里调用一个函数并不意味着生成的目标代码里也会做一次真正的函数调用(可能看不到call指令)。现在的编译器聪明到可以自动判断一个函数是否适合inline,因此inline关键字在源文件中往往不是必需的。当然,在头文件中inline还是要的,为了防止链接器抱怨重复定义(multiple definition)。现在的C++编译器采用重复代码消除的办法来避免重复定义。也就是说,如果编译器无法inline展开的话,每个编译单元都会生成inline函数的目标代码,然后链接器会从多份实现中任选一份保留,其余的则丢弃(vague linkage)。如果编译器能够展开inline函数,那就不必单独为之生成目标代码了(除非使用函数指针指向它)。
如何判断一个C++可执行文件是debug build还是release build?换言之,如何判断一个可执行文件是-O0编译还是-O2编译?我通常的做法是看class template的短成员函数有没有被inline展开。例如:
1 | |
g++ -Wall vec.cc
nm -C /a.out | grep size
c++filt
注意,编译器为我们自动生成的class析构函数也是inline函数,有时候我们要故意out-line,防止代码膨胀或出现编译错误。以下Printer是依据后面\(\S11.4\)介绍的pimpl手法实现的公开class。这个class的头文件完全没有暴露Impl class的任何细节,只用到了前向声明。并且有意地把构造函数和析构函数也显式声明了。
1 | |
在源文件中,我们可以从容地先定义Printer::Impl,然后再定义Printer的构造函数和析构函数。
1 | |
在现代的C++系统中,编译和链接的界限更加模糊了。传统C++教材告诉我们要想编译器能够inline一个函数,那么这个函数体必须在当前编译单元可见。因此我们通常把公共inline函数放到头文件中。现在有了link time code generation,编译器不需要看到inline函数的定义,inline展开可以留给链接器去做。
除了inline函数,g++还有大量的内置函数,因此源代码中出现memcpy、memset、strlen、sin、exp之类的“函数调用”不一定真的会调用bc里的库函数。另外,由于编译器知道这些函数的功能,因此优化起来更充分。例如muduo日志库就使用了内置strchr()函数在编译期求出文件的basename。
有意思的是,编译器如何处理inline两数中的static变量?这个留给有兴趣的读者去探究吧。
3.3 模板
C++模板包括函数模板和类模板,与链接相关的话题包括:
- 函数定义,包括具现化后的函数模板、类模板的成员函数,类模板的静态成员函数等。
- 变量定义,包括函数模板的静态数据变量、类模板的静态数据成员、类模板的全局对象等。
模板编译链接的不同之处在于,以上具有external linkage的对象通常会在多个编译单元被定义。链接器必须进行重复代码消除,才能正确生成可执行文件。
template和inline函数会不会导致代码膨胀
假设有一个定长Buffer类,其内置buffer长度是在编译期确定的,我们可以把它实现为非类型类模板:
1 | |
在代码中使用了Buffer<256>和Buffer<1024>两份具现体:
1 | |
按照C++模板的具现化规则,编译器会为每一个用到的类模板成员函数具现化一份实体。
g++ buffer.cc
nm a.out
这样看来真的造成了代码膨胀,但实际情况并不一定如此,如果我们用-O2编译一下,会发现编译器把这些短函数都inline展开了。
g++ -O2 buffer.cc
nm a.out | c++filt
如果我们想限制模板的具现化,比方说限制Buffer只能有64、256、1024、4096这几个长度,除了可以用static_assert来制造编译期错误,还可以用下面这个只声明、不定义的办法来制造链接错误。
一般的C++教材会告诉你,模板的定义要放到头文件中,否则会有编译错误。如果读者足够细心,会发现其实所谓的“编译错误”是链接错误。例如:
1 | |
只声明而没有定义
1 | |
只声明而没有定义
g++ main.cc
nm main.o
g++ -c main.cc
nm main.o
g++ main.o foo.o
对于通用(universal)的模板库,这个办法是行不通的,因为你不可能事先知道客户会用哪些参数类型来具现化你的模板(比如vector<T>和shared_ptr<T>)。但是对于某些特殊情况,这可以减少代码膨胀,比如把Buffer<int>的构造函数从头文件移到某个源文件,并且只具现化几个固定的长度,这样防止客户代码任意具现化Buffer模板。
对于private成员函数模板,我们也不用在头文件中给出定义,因为用户代码不能调用它,也就无法随意具现化它,所以不会造成链接错误。考虑下面这个多功能打印机的例子,Printer既能打印,也能扫描。PrintRequest和ScanRequest都是由代码生成器生成的class,它们有一些共同的成员,但是没有共同的基类。
1 | |
我们写一个Printer class,能同时处理这两种请求,为了避免代码重复,我们打算用一个函数模板来解析request的公共部分。
1 | |
这个decodeRequest是模板,但不必把实现暴露在头文件中,因为只有onRequest会调用它。我们可以把这个成员函数模板的实现放到源文件中。这样的好处之一是Printer的用户看不到decodeRequest函数模板的定义,可以加快编译速度。
1 | |
前面展示的几种template用法一般不会用在通用的模板库中,因此很少有书籍或文章谈到它们。在编写应用程序的时候适当使用模板能减少重复劳动,降低出错的可能,值得了解一下。
另外,C++11新增了extern template特性,可以阻止隐式模板具现化。g++很早支持这个特性,g++的C++标准库就使用了这个办法,使得使用std::string和std::iostream的代码不受代码膨胀之苦。
3.4 虚函数
在现在的C++实现中,虚函数的动态调用(动态绑定、运行期决议)是通过虚函数表(vtable)进行的,每个多态class都应该有一份vtable。定义或继承了虚函数的对象中会有一个隐含成员:指向vtable的指针,即vptr。在构造和析构对象的时候,编译器生成的代码会修改这个vptr成员,这就要用到vtable的定义(使用其地址)。因此我们有时看到的链接错误不是抱怨找不到某个虚函数的定义,而是找不到虚函数表的定义。例如:
1 | |
g++ virt.cc
/tmp/cc8Q7qki.o:In function Base::Base()':
virt.cc:(.text+0x17): undefined reference to 'vtable for Base'
collect2: ld returned 1 exit status
出现这种错误的根本原因是程序中某个虚函数没有定义,知道了这个方向,查找问题就不难了。
另外,按道理说,一个多态class的vtable应该恰好被某个目标文件定义,这样链接就不会有错。但是C++编译器有时无法判断是否应该在当前编译单元生成vtable定义,为了保险起见,只能每个编译单元都生成vtable,交给链接器去消除重复数据。有时我们不希望vtable导致目标文件膨胀,可以在头文件的class定义中声明out-line虚函数。
1 | |
4. 工程项目中头文件的使用规则
4.1 头文件的害处
我认为头文件的害处主要体现在以下几方面:
- 传递性:头文件可以再包含其他头文件。前面已经举过例子,一个简单的
#include<complex>展开之后有两万多行代码,一方面造成编译缓慢,另一方面,任何一个头文件改动一点点代码都会需要重新编译所有直接或间接包含它的源文件。因为buildtool无法有效判断这个改动是否会影响程序语义,保守起见只能把受影响的源文件全部重新编译一遍。因此,合理组织源代码,减少开发时rebuild的成本是每个稍具规模项目的必做功课。 - 顺序性:一个源文件可以包含多个头文件。如果头文件内容组织不当,会造成程序的语义跟文件包含的顺序有关,也跟是否包含某一个头文件有关。通常的做法是把头文件分为几类,然后分别按顺序包含这几类头文件,相同类的头文件按文件名的字母排序。这样一方面源代码比较整洁;另一方面如果两个人同时修改源码,各自想多包含一个头文件,那么造成冲突的可能性较小。一般应该避免每次在
#include列表的末尾添加新的头文件,这样很快代码的依赖关系就无法管理了。 - 差异性:内容差异造成不同源文件看到的头文件不一致,时间差异造成头文件与库文件内容不一致。例如12.7提到不同的编译选项会造成Visual
C++
std::string的大小不一样。也就是说<string>头文件的内容经过预处理后会有变化,如果两个源文件编译时的宏定义选项不一致,可能造成二进制代码不兼容。这说明整个程序应该用统一的编译选项的。如果程序用到了第三方静态库或者动态库,除了拿到头文件和库文件,我们还要拿到当时编译这个库的编译选项,才能安全无误地使用这个程序库。如果程序用到了两个库,但是它们的编译选项有冲突,那麻烦就大了,后面谈库文件组织的时候再来说这个问题和时间差异的问题。
反观现代的编程语言,它们比C++的历史包袱轻多了,模块化做得也比较好。模块化的做法主要有两种:
- 对于解释型语言,import的时候直接把对应模块的源文件解析(parse),不再是简单地把源文件包含进来。
- 对于编译型语言,编译出来的目标文件(例如Java的.class文件)里直接包含了足够的元数据,import的时候只需要读目标文件的内容,不需要读源文件。
这两种做法都避免了声明与定义不一致的问题,因为在这些语言中声明与定义是一体的。同时这种import手法也不会引入不想要的名字,大大简化了名字查找的负担(无论是人脑还是编译器),也不用担心import的顺序不同造成代码功能变化。
4.2 头文件的使用规则
几乎每个C++编程规范都会涉及头文件的组织。归纳起来观点如下:
- 将文件间的编译依赖降至最小。[EC3,条款31]
- 将定义式之间的依赖关系降至最小,避免循环依赖。[CCS,条款22]
- 让class名字、头文件名字、源文件名字直接相关。这样方便源代码的定位。muduo源码遵循这一原则,例如TcpClient class的头文件是TcpClient.h,其成员函数定义在TcpClient.cc。
- 令头文件自给自足。[CCS,条款23]例如要使用muduo的TcpServer,可以直接包含TcpServer.h。为了验证TcpServer.h的自足性(self-contained),TcpServer.cc第一个包含的头文件就是它。
- 总是在头文件内写内部#include guard(护套),不要在源文件写外部护套。[CCS.条款24]这是因为现在的预处理对这种通用做法有特别的优化,GNU cpp在第二次#include同一个头文件时甚至不会去读这个文件,而是直接跳过。
- #include guard用的宏的名字应该包含文件的路径全名(从版本管理器的角度),必要的话还要加上项目名称(如果每个项目有自己的代码仓库)。
- 如果编写程序库,那么公开的头文件应该表达模块的接口,必要的时候可以把实现细节放到内部头文件中。muduo的头文件满足这条规则(p.130)。
遵循以上规则,作为应用程序的作者,一般就不会遇到跟头文件和预处理相关的问题。这里介绍一个查找头文件包含途径的小技巧。比方说有一个程序只包含了<iostream>,但是却能使用std::string,我想知道<string>是如何被引入的。办法是在当前目录创建一个string文件,然后制造编译错误,步骤如下:
1 | |
1 | |
下面我们谈谈在编写和使用库的时候应该注意些什么。
5. 工程项目中库文件的组织原则
考虑一个具有一定规模的公司,有一个基础库团队,开发并维护公司的公共C++网络库net;还有个团队开发了一套消息中间件,并提供了一个客户端库hub,hub是基于net构建的;最近公司又有另外一个团队开发了一套存储系统,并提供了一个客户端库cab,cab也是基于net构建的。公司内部开发的服务端程序可能会用到这些库的一个或几个,本节主要讨论如何组织这些由不同团队开发的库与应用程序。
在谈具体的C++库文件的组织之前,先谈一谈依赖管理。
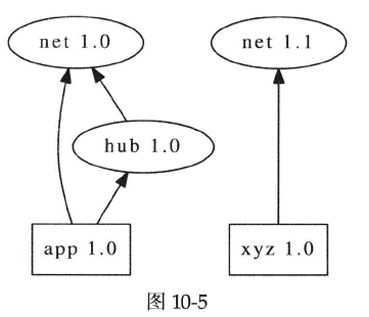
假设你负责实现并维护一个关键的网络服务程序app,经过充分测试之后,app 1.0上线运行,一切顺利。app 1.0用到了网络库(net 1.0)和消息中间件的客户端库(hub 1.0),并且hub 1.0本身也用到了net 1.0,依赖关系如图10-3所示。
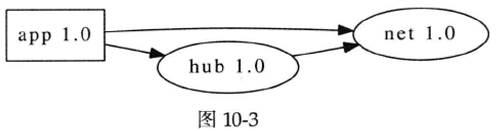
尽管在发布之前QA人员sign-off的是app 1.0,但是我们应该认为他们sign-off的是app 1.0和它依赖的所有库构成的bundle。因为app的行为跟它用到的库有关,如果改变其中任何一个库,app的行为都可能发生变化(尽管app的源码和可执行文件一个字节都没动),也就可能跟当时充分测试通过的“app 1.0”行为不一致。
周伟明老师在《软件测试实践》的第1.7.2节“COM的可测试性分析”中明确表示,COM“违反了软件设计的基本原理”,其理由是:
我们假设一个软件包含n个不同的COM组件,按照COM的设计思想,每个组件都是可以替换的。假设每个组件都有若干个不同的版本,记为分别有M1, M2, ..., M个不同的版本,那么组成整个软件的所有组件的组合关系有M1 × M2 × ... × Mn种,等于这个软件共有M1 × M2 × ... × Mn种二进制版本。如果要将测试做得充分,这些组合全部都需要进行测试,否则很难保证没测试到的组合不会有问题。
这至少从理论上说明,改动程序本身或它依赖的库之后应该重新测试,否则测试通过的版本和实际运行的版本根本就是两个东西。一旦出了问题,责任就难理清了。
这个问题对C++之外的语言也同样存在,我认为凡是可以在编译之后替换库的语言都需要考虑类似的问题。对于脚本语言来说,除了库之外,解释器的版本(Python 2.5/2.6/2.7)也会影响程序的行为,因此有Python virtualenv和Ruby rbenv这样的工具,允许一台机器同时安装多个解释器版本。Java程序的行为除了跟classpath里的那些jar文件有关,也跟JVM的版本有关,通常我们不能在没有充分测试的情况下升级JVM的大版本(从1.5到1.6)。
除了库和运行环境,还有一种依赖是对外部进程的依赖,例如app程序依赖某些数据源(运行在别的机器上的进程),会在运行的时候通过某种网络协议从这些数据源定期或不定期读取数据。数据源可能会升级,其行为也可能变化,如何管理这种依赖就超出本节的范围了。
回到C++,首先谈编译器版本之间的兼容性。截至g++ 4.4,Linux目前已有四个互不兼容的ABI版本,编译出来的库互不通用:
- gcc 3.0之前的版本,例如2.95.3
- gcc 3.0/3.1
- gcc 3.2/3.3
- gcc 3.4~4.4
现在看来,这其实影响不大,因为估计没有谁还在用g++ 3.x来编译新的代码。
另外一个需要考虑的是C++标准库(libstdc++)的版本与C标准库(glibc)的版本。C++标准库的版本跟C++编译器直接关联,我想一般不会有人去替换系统的libstdc++。C标准库的版本跟Linux操作系统的版本直接相关,见表10-1。一般也不会有人单独升级glibc,因为这基本上意味着需要重新编译用户态的所有代码。
另外,为了稳要起见,通常建议用Linux发行版自带的那个gcc版本来编译你的代码。因为这个版本的gcc是Linux发行版主要支持的编译器版本,当前kernel和用户态的其他程序也基本是它编译的,如果它有什么问题的话,早就被人发现了。
根据以上分析,一旦选定了生产环境中操作系统的版本,另外三样东西的版本就确定了。我们暂且认为生产环境中运行app 1.0的机器的Linux操作系统版本、libstdc++版本、glibc版本是统一的,而且C++应用程序和库的代码都是用操作系统原生的g++来编译的。表10-1列出了几大主流Linux发行版的版本配置。
表10-1
| Distro | Kernel | gcc | glibc |
|---|---|---|---|
| RHEL 6 | 2.6.32 | 4.4.6 | 2.12 |
| RHEL 5 | 2.6.18 | 4.1.2 | 2.5 |
| RHEL 4 | 2.6.9 | 3.4.6 | 2.3.4 |
| Debian 6.0 | 2.6.32 | 4.4.5 | 2.11.2 |
| Debian 5.0 | 2.6.26 | 4.3.2 | 2.7 |
| Debian 4.0 | 2.6.18 | 4.1.1 | 2.3.6 |
| Ubuntu 10.04LTS | 2.6.32 | 4.4.3 | 2.11.1 |
| Ubuntu 8.04LTS | 2.6.24 | 4.2.3 | 2.7 |
| Ubuntu 6.04LTS | 2.6.15 | 4.0.3 | 2.3.6 |
升级操作系统时这三个都会一起变,那时候程序几乎肯定要重新测试并重新部署上线。
这样一来,我们就可以在C++编译器版本,C++标准库版本、C标准库版本均固定的情况下来讨论应用程序与库的组织。进一步说,这里讨论的是公司内部实现的库,而不是操作系统自带的编译好的库(libz、libssl、libcurl等等)。后面这些库可以通过操作系统的package管理机制来统一部署,确保每台机器的环境相同。
Linux的共享库(shared library)比Windows的动态链接库在C++编程方面要好得多,对应用程序来说基本可算是透明的,跟使用静态库无区别。主要体现在:
- 一致的内存管理。Linux动态库与应用程序共享同一个heap,因此动态库分配的内存可以交给应用程序去释放,反之亦可。
- 一致的初始化。动态库里的静态对象(全局对象、namespace级的对象等等)的初始化和程序其他地方的静态对象一样,不用特别区分对象的位置。
- 在动态库的接口中可以放心地使用class、STL、boost(如果版本相同)。
- 没有dllimport/dllexport的累赘。直接include头文件就能使用。
- DLL Hell的问题也小得多,因为Linux允许多个版本的动态库并存,而且每个符号可以有多个版本。
DLL Hell指的是安装新的软件的时候更新了某个公用的DLL,破坏了其他已有软件的功能。例如安装xyz 1.0会把net库升级为1.1版,覆盖了原来app 1.0和hub 1.0依赖的net 1.0,这有潜在的风险(图10-4)。
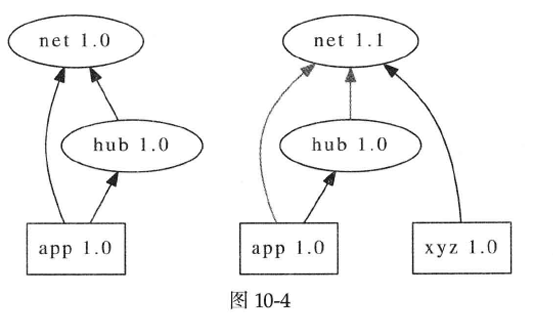
现在Windows 7里有side-by-side assembly,基本解决了DLL Hell问题,代价是系统里有一个巨大的且不断增长的WinSxS目录。
一个C++库的发布方式有三种:动态库(.so)、静态库(.a)、源码库(.cc)。表10-2简单总结了一些基本特性。
表10-2
| 特性 | 动态库 | 静态库 | 源码库 |
|---|---|---|---|
| 库的发布方式 | 头文件+.so文件 | 头文件+.a文件 | 头文件+.cc文件 |
| 程序编译时间 | 短 | 短 | 长 |
| 查询依赖 | 运行时查询 | 编译期信息 | 编译期信息 |
| 部署 | 可执行文件+动态库 | 单一可执行文件 | 单一可执行文件 |
| 主要时间差 | 编译时 | 编译时 | 运行时 |
本节谈动态库只包括编译时就链接动态库的那种常规用法,不包括运行期动态加载(dlopen())的用法。
作为应用程序的作者,如果要在多台Linux机器上运行这个程序,我们先要把它部署(deploy)到那些机器上。如果程序只依赖操作系统本身提供的库(包括可以通过package管理软件安装的第三方库),那么只要把可执行文件拷贝到目标机器上就能运行。这是静态库和源码库在分布式环境下的突出优点之一。
相反,如果依赖公司内部实现的动态库,这些库必须事先(或者同时)部署到这些机器上,应用程序才能正常运行。这立刻就会面临运维方面的挑战:部署动态库的工作由谁(库的作者还是应用程序的作者)来做呢?另外一个相关的问题是,如果动态库的作者修正了bug,他可以自主更新所有机器上的库吗?
我们暂且认为库的作者可以独立地部署并更新动态库,并且影响到使用这个库的应用程序。否则的话,如果每个程序都把自己已用到的动态库和应用程序一起打包发布,库的作者不负责库的更新,那么这和使用静态库就没有区别了,还不如直接静态链接。
无论哪种方式,我们都必须保证应用程序之间的独立性,也就是让动态库的多个大版本能够并存。例如部署app 1.0和xyz 1.0之后的依赖关系如图10-5所示。
按照传统的观点,动态库比静态库节省磁盘空间和内存空间,并且具备动态更新的能力(可以hotfix bug),似乎动态库应该是目前的首选。但是正是这种动态更新的能力让动态库成了烫手的山芋。
5.1 动态库是有害的
Jeffrey Richter对动态库的本质问题有精辟的论述:
一旦替换了某个应用程序用到的动态库,先前运行正常的这个程序使用的将不再是当初build和测试时的代码。结果是程序的行为变得不可预期。
怎样在fix bug和增加feature的同时,还能保证不会损坏现有的应用程序?
我(Jeffrey Richter)曾经对这个问题思考了很久,并且得出了一个结论——那就是这是不可能的。
作为库的作者,你肯定不希望更新部署一个看似有益无害的bug fix之后,星期一早上被应用程序的维护者的电话吵醒,说程序不能启动(新的库破坏了二进制兼容性)或者出现了不符合预期的行为。
作为应用程序的作者,你也肯定不希望星期一一大早被运维的同事吵醒,说你负责的某个服务进程无法启动或者行为异常。经排查,发现只有某一个动态库的版本与上星期不同。你该朝谁发火呢?
既然双方都不想过这种提心吊胆的日子,那为什么还要用动态库呢?
那么有没有可能在发布动态库的bug fix之前充分测试所有受影响的应用程序呢?这会遇到一个两难命题:一个动态库的使用面窄,只有两三个程序用到它,测试的成本较低,那么它作为动态库的优势就不明显。相反,一个动态库的使用面宽,有几十个程序用到它,动态库的“优势”明显,测试和更新的成本也相应很高(或许高到足以抵消它的“优势”)。有一种做法是把动态库的更新先发布到QA环境,正常运行一段时间之后再发布到生产环境,这么做也有另外的问题:你在测试下一版app 1.1的时候,该用QA环境的动态库版本还是用生产环境的动态库版本?如果程序在编译测试之后行为还会改变,这是不是在让QA白费力气?
总之,一旦动态库可能频繁更新,我没有发现一个完美的使用动态库的办法。在决定使用动态库之前,我建议至少要熟悉它的各种陷阱。参考资料如下:
- http://harmful.cat-v.org/software/dynamic-linking/
- 《A Quick Tour of Compiling, Linking, Loading, and Handling Libraries on Unix》(http://ref.web.cern.ch/ref/CERN/CNL/2001/005/shared-lib/Pr/)。
- 《How to write shared libraries》(http://www.akkadia.org/drepper/dsohowto.pdf)。
- 《Good Practices in Library Design, Implementation, and Maintenance》(http://www.akkadia.org/drepper/goodpractice.pdf)。
- 《Solaris Linker and Libraries Guide》(http://docs.oracle.com/cd/E19963-01/html/819-0690/)。
- 《Shared Libraries in SunOS》(http://www.cs.cornell.edu/courses/cs414/2004fa/sharedlib.pdf)。
5.2 静态库也好不到哪儿去
静态库相比动态库主要有几点好处:
- 依赖管理在编译期决定,不用担心日后它用的库会变。同理,调试core dump不会遇到库更新导致debug符号失效的情况。
- 运行速度可能更快,因为没有PLT(过程查找表),函数调用的开销更小。
- 发布方便,只要把单个可执行文件拷贝到目标机器上。
静态库的一个小缺点是链接比动态库慢,有的公司甚至专门开发了针对大型C++程序的链接器。
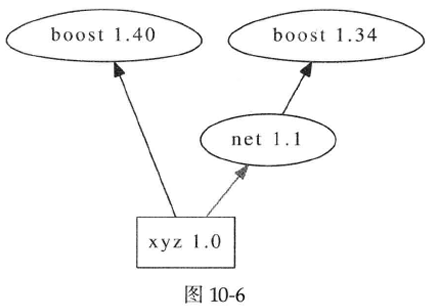
静态库的作者把源文件编译成.a库文件,连同头文件一起打包发布。应用程序的作者用库的头文件编译自己的代码,并链接到.a库文件,得到可执行文件。这里有一个编译的时间差:编译库文件比编译可执行文件要早,这就可能造成编译应用程序时看到的头文件与编译静态库时不一样。
比方说编译net 1.1时用的是boost 1.34,但是编译xyz这个应用程序的时候用的是boost 1.40,这种不一致有可能导致编译错误,或者更糟糕地导致不可预期的运行错误。比方说net库以boost::function提供回调,但是boost 1.36去掉了一个模板类型参数,造成xyz 1.0用boost 1.40的话就与net 1.1不兼容。
这说明应用程序在使用静态库的时候必须要采用完全相同的开发环境(更底层的库、编译器版本、编译器选项)。但是如果两个静态库的依赖有冲突怎么办?
静态库把库之间的版本依赖完全放到编译期,这比动态库要省心得多,但是仍然不是一件容易的事情。下面略举几种可能遇到的情况:
- 强制升级高版本。
- 重复链接。
- 版本冲突。
可见静态库的版本管理并不如想象中那么简单。如果一个应用程序用到了三四个公司内部的静态库,那么协调库之间的版本要花一番脑筋,单独升级任何一个库都可能破坏它原本的依赖。
静态库的演化也比较费事。到目前为止我们认为公司没有历史包袱,所有的机器都是2009年前后买的,运行的是Ubuntu 8.04 LTS,软件版本是g++ 4.2、glibc 2.7、boost 1.34等等,C++程序和库也都是在这个统一的环境下开发的。现在到了2012年,线上服务器已服役满3年,进入换代周期。新购买的机器打算升级到Ubuntu 10.04 LTS,因为新内核的驱动程序对新硬件支持更好,而且8.04版还有一年多就停止支持了。这样同时升级了内核、gcc 4.4、glibc 2.11、boost 1.40。
这就要求静态库的作者得为新系统重新编译并发布新的库文件。为了避免混淆,我们不得不为库加上后缀名,以标明环境和依赖。假设目前有net 1.0、net 1.1、net 1.2、hub 1.0、hub 1.1、cab 1.0等现役的库,那么需要发布多个版本的静态库
这种组合爆炸式的增长让人措手不及,因为任何一个底层库新增一个变体(variant),所有依赖它的高层库都要为之编译一个版本。
如果这些库打算支持C++11,那么上面这个列表还会长50%,因为g++为C++11修改了ABI,即使用--std=c++0x参数编译出来的库文件不能与旧的C++库混用。
要想摆脱这个困境,我能想到的办法是使用源码库,即每个应用程序都从头编译所需的库,把时间差减到最小。
5.3 源码编译是王道
每个应用程序自已选择要用到的库,并自行编译为单个可执行文件。彻底避免文件与库文件之间的时间差,确保整个项目的源文件采用相同的编译选项,也不用为库的版本搭配操心。这么做的缺点是编译时间很长,因为把各个库的编译任务从库文件的作者转嫁到了每个应用程序的作者。
另外,最好能和源码版本工具配合,让应用程序只需指定用哪个库,build工具能自动帮我们checkout库的源码。这样库的作者只需要维护少数几个branch,发布库的时候不需要把头文件和库文件打包供人下载,只要push到特定的branch就行。而且这个build工具最好还能解析库的Makefile(或等价的build script),自动帮我们解决库的传递性依赖,就像Apache Ivy能做的那样。
在目前看到的开源build工具里,最接近这一点的是Chromium的gyp和腾讯的typhoon-blade,其他如SCons、CMake、Premake、Waf等等工具仍然是以库的思路来搭建项目。
总结
由于C++的头文件与源文件分离,并且目标文件里没有足够的元数据供编译器使用,因此必须同时提供库文件和头文件。也就是说要想使用一个已经编译好的C/C++库(无论是静态库还是动态库),我们需要两样东西,一是头文件(.h),二是库文件(.a或.so),这就存在了这两样东西不匹配的可能。这是造就C++简陋脆弱的模块机制的根本原因。C++库之间的依赖管理远比其他现代语言复杂,在编写程序库和应用程序时,要熟悉各种机制的优缺点,采用开发及维护成本较低的方式来组织和发布库。