11. 反思C++面向对象与虚函数
第11章 反思C++面向对象与虚函数
C++的面向对象语言设施相比其他现代语言可算得上“简陋”,而且与语言的其他部分(better C、数据抽象、泛型)融合度较差(见电子工业出版社出版的《C++ Primer(第4版)(评注版)》第15章)。在C++中进行面向对象编程会遇到其他语言中不存在的问题,其本质原因是C++ class是值语义,而非对象语义。
1. 朴实的C++设计
C++是一门(最)复杂的编程语言,语言虽复杂,不代表一定要用复杂的方式来使用它。对于一个金融交易系统,正确性是首要的,价格/数量/交割日期弄错了就会赔钱。在编写代码时,我们特别注意把代码写得尽量简单直白,让人一看就懂。为了控制代码的复杂度,我们采用了基于对象的风格,也就是具体类加全局函数,把C++程序写得如C语言一般清晰,同时使用一些C++特性和库来减少代码。
项目中基本没有用到面向对象,或者说没有用到继承和多态的那种面向对象(不一定非得有基类和派生类的设计才是好设计)。引入基类和派生类,或许能带来灵活性,但是代码就不如原来透彻了。在不需要这种灵活性的场合,为什么要付出这样的代价呢?我宁愿花一天时间把几千行C代码弄懂,也不愿在几千个类组成的继承体系里绕来绕去浪费脑力。定义并使用清晰一致的接口很重要,但“接口”不一定非得是抽象基类,一个类的成员函数就是它的接口。如果看头文件就能明白这个类在干什么、该怎么用固然很好,但如果不明白,打开实现文件,东西都在那儿摆着呢,一望而知。没必要非得用个抽象的接口类把使用者和实现隔开,再把实现隐藏起来,这除了让查找并理解代码变麻烦之外没有任何好处。一个进程内部的解耦意义不大:相反,函数调用是最直接有效的通信方式。或许采用接口类/实现类的一个可能的好处是依赖注入,便于单元测试。经过权衡比较,我们发现针对各个类写测试的意义不大。另外,如果用黑盒测试,那么功能代码和测试代码就得同步更新,会增加不少工作量,碍手碍脚。
程序里边有一处用到了继承,因为它能简化设计。这是一个strategy,涉及一个基类和三四个派生类,所有的类都没有数据成员,只有虚函数。这几个类的代码加起来不到200行。这个设计不是一开始就有的,而是在项目进行了一大半的时候,我们发现代码里有若干处针对请求类型的switch-case,于是提炼出了一个strategy,把好几处switch-case替换为了strategy对象的虚函数调用,从而简化了代码。这里我们是把OO纯粹当做函数指针表来用的。
程序里还有几处用了模板,甚至为了简化与第三方库的交互而动用了type_traits,这都是为了简化代码,最少键盘。这些代码都藏在一个角落里,对外只暴露出一个全局函数的接口,使用者不会被其困扰。
项目里,我们唯一仰仗的C++特性是确定性析构,即一个对象在离开其作用域之后会保证调用析构函数。我们利用这点大大简化了代码,并确保资源和内存的回收。在我看来,确定性析构是C++区别其他主流开发语言(Java/C#/C/动态脚本语言)的最主要特性。
为了确保正确性,我们另外用Java写了一个测试夹具(test harness)来测试我们这个C++程序。这个测试夹具模拟了所有与我们这个C++程序打交道的其他程序,能够测试各种正常或异常的情况。基本上任何代码改动和bug修复都在这个夹具中有体现。如果要新加一个功能,会有对应的测试用例来验证其行为。如果发现了一个bug,先往夹具里加一个或几个能复现bug的测试用例,然后修复代码,让测试通过。我们积累了几百个测试用例,这些用例表示了我们对程序行为的预期,是一份可以运行的文档。每次代码改动提交之前,我们都会执行一通测试,以防低级错误发生。(见本书\(\S9.7\)的详细论述和S7.12的例子。)
我们让每个类有明确的职责范围,一个类代表一个概念,不能像个杂货铺一样什么都装。在增加或修改功能的时候,仔细考虑在哪儿下手才最合理。必要时可以动大手脚,而不是每次都选择最简单的修补方式,那样只会使代码越来越臭,积重难返,重蹈上一个版本的覆辙。有时我们会提炼出一个新的类,把原来分散在多个类里的代码集中到一起,从而优化结构。我们有测试夹具保障,并不担心修改会破坏什么。
设计不是一开始就形成的,而是随着项目进展逐步演化出来的。我们的设计是基于类的,而不是基于类的继承体系的。我们是在写应用,不是在写框架,在C++重用那么多继承对我们没好处。一开始我们只有三四个类,实现了基本的报价功能,然后增加了一个类,实现了下单功能。这时我们把报价和下单的共同数据结构提炼成一个新的类,作为原来两个类的成员(而不是基类!),并把解析客户输入的代码移到这个类里。我们的原则是,可以有特别简单的类,但不宜有特别复杂的类,更不能有“大类”。一个类太大,我们就看看能不能把它拆成两个,把责任分开。两个类有共同的代码逻辑,我们会考虑提炼出一个工具类来用,输入数据的验证就是这么提炼出来的一个类。勿以善小而不为,应始终让代码保持清晰易懂。
让代码保持清晰,给我们带来了显而易见的好处。错误更容易暴露,在发布前多修复一个错误,发布后就少一次半夜被从被窝里叫醒查错的机会。
不要因为某个技术流行而去用它,除非它确实能降低程序的复杂性。毕竟,软件开发的首要技术使命是控制复杂度,防止脑袋爆掉。对于继承要特别小心,这条“贼船”上去就下不来,除非你是继承boost::noncopyable。在讲解面向对象的书里,总会举一些用继承的精巧的例子,比如矩形、正方形、圆形继承自形状,飞机和麻雀继承自“能飞的”,这不意味着继承处处适用。我认为在C++这样需要自己管理内存和对象生命周期的语言里,大规模使用面向对象、继承、多态多是自讨苦吃。还不如用C语言的思路来设计,在局部用一用继承来代替函数指针表。而《设计模式》与其说是常见问题的解决方案,不如说是绕过(workaround)C++语言限制的技巧。当然,也是一些人挂在嘴边用来忽悠别人或麻痹自己的灵丹妙药。
2. 程序库的二进制兼容性
本节主要讨论Linux x86/x86-64平台,偶尔会举Windows作为反面教材。
C++程序员有不同的角色,比如有主要编写应用程序的(application),也有主要编写程序库的(library),有的程序员或许还身兼多职。如果公司的规模比较大,会出现更细致和明确的分工。比如有的团队专门负责一两个公用的library:有的团队负责某个application,并使用了前一个团队的library。
举一个具体的例子。假设你负责一个图形库,这个图形库功能强大,且经过了充分测试,于是在公司内慢慢推广开来。目前已经有二三十个内部项目用到了你的图形库,大家日子过得挺好。前几天,公司新买了一批大屏幕显示器(分辨率为2560×1600像素),不巧你的图形库不能支持这么高的分辨率。(这其实不怪你,因为在你当年编写这个库的时候,市面上显示器的最高分辨率是1920×1200像素。)结果用到了你的图形库的应用程序在2560×1600分辨率下不能正常工作,你该怎么办?你可以发布一个新版的图形库,并要求那二三十个项目组用你的新库重新编译他们的程序,然后让他们重新发布应用程序。或者,你提供一个新的库文件,直接替换现有的库文件,应用程序的可执行文件保持不变。
这两种做法各有优劣。第一种做法声势浩大,凡是用到你的库的团队都要经历一个release cycle。后一种做法似乎节省人力,但是有风险:如果新的库文件和原有的应用程序可执行文件不兼容怎么办?
所以,作为C++程序员,只要工作涉及二进制的程序库(特别是动态库),都需要了解二进制兼容性方面的知识。
C/C++的二进制兼容性(binary compatibility)有多重含义,本文主要在“库文件单独升级,现有可执行文件是否受影响”这个意义下讨论,我称之为library(主要是shared library,即动态链接库)的ABI(application binary interface)。至于编译器与操作系统的ABI见第10章。
2.1 什么是二进制兼容性
在解释这个定义之前,先看看Unix和C语言的一个历史问题:open()的flags参数的取值。open(2)函数的原型如下,其中flags的取值有三个:O_RDONLY、O_WRONLY、O_RDWR。
1 | |
与人们通常的直觉相反,这几个常数值不满足按位或(bitwise-OR)的关系,即(O_RDONLY | O_WRONLY) != O_RDWR。如果你想以读写方式打开文件,必须用O_RDWR,而不能用(O_RDONLY | O_WRONLY)。为什么?因为O_RDONLY、O_WRONLY、O_RDWR的值分别是0、1、2。它们不满足按位或。
那么为什么Unix/C语言从诞生到现在一直没有纠正这个小小的缺陷?比方说把O_RDONLY、O_WRONLY、O_RDWR分别定义为1、2、3这样(O_RDONLY | O_WRONLY)O_RDWR,符合直觉。而且这三个值都是宏定义,也不需要修改现有的源代码,只需要改改系统的头文件就行了。
这么做会破坏二进制兼容性。对于已经编译好的可执行文件,它调用open(2)的参数是写死的,更改头文件并不能影响已经编译好的可执行文件。比方说这个可执行文件会调用open(path, 1)来写文件,而在新规定中,这表示读文件,程序就错乱了。
以上这个例子说明,如果以shared library方式提供函数库,那么头文件和库文件不能轻易修改,否则容易破坏已有的二进制可执行文件,或者其他用到这个shared library的library。
操作系统的system call可以看成Kernel与Userspace的interface,kernel在这个意义下也可以当成shared library,你可以把内核从2.6.30升级到2.6.35,而不需要重新编译所有用户态的程序。
本章所指的“二进制兼容性”是在升级(也可能是bug fix)库文件的时候,不必重新编译使用了这个库的可执行文件或其他库文件,并且程序的功能不被破坏。见QT FAQ的有关条款。
在Windows有臭名昭著的DLL Hell问题,比如MFC有一堆DLL:mfc40.dll、mfc42.dll、mfc71.dll、mfc80.dll、mfc90.dll等,这其实是动态链接库的本质问题,怪不到MFC头上。
2.2 有哪些情况会破坏库的ABI
到底如何判断一个改动是不是二进制兼容呢?这跟C++的实现方式直接相关,虽然C++标准没有规定C++的ABI,但是几乎所有主流平台都有明文或事实上的ABI标准。比方说ARM有EABI,Intel Itanium有Itanium ABI,x86-64有仿Itanium的ABI,SPARC和MIPS也都有明文规定的ABI,等等。x86是个例外,它只有事实上的ABI,比如Windows就是Visual C++,Linux是G++(G++的ABI还有多个版本,目前最新的是G++3.4的版本),Intel的C++编译器也得按照Visual C++或G++的ABI来生成代码,否则就不能与系统的其他部件兼容。
C++编译器ABI的主要内容包括以下几个方面:
- 函数参数传递的方式,比如x86-64用寄存器来传函数的前4个整数参数;
- 虚函数的调用方式,通常是vptr/vtbl机制,然后用vtbl[offset]来调用;
- struct和class的内存布局,通过偏移量来访问数据成员;
- name mangling;
- RTTI和异常处理的实现(以下本文不考虑异常处理)。
C/C++通过头文件暴露出动态库的使用方法(主要是函数调用和对象布局),这个“使用方法”主要是给编译器看的,编译器会据此生成二进制代码,然后在运行的时候通过装载器(loader)把可执行文件和动态库绑到一起。如何判断一个改动是不是二进制兼容,主要就是看头文件暴露的这份“使用说明”能否与新版本的动态库的实际使用方法兼容。因为新的库必然有新的头文件,但是现有的二进制可执行文件还是按旧的头文件中的“使用说明”来调用动态库。
先说修改动态库导致二进制不兼容的例子。比如原来动态库里定义了non-virtual函数void foo(int),新版的库把参数改成了double。那么现有的可执行文件就无法启动,会发生undefined
symbol错误,因为这两个函数的mangled
name不同。但是对于virtual函数foo(int),修改其参数类型并不会导致加载错误,而是会发生异的运行时错误。因为虚函数的决议(resolution)是靠偏移量,并不是靠符号名。
再举一些源代码兼容但是二进制代码不兼容的例子:
给函数增加默认参数,现有的可执行文件无法传这个额外的参数。
增加成员函数,会造成vtbl重的排列变化。(不要考虑“只在未尾增加”这种取巧行为,因为你的class可能已被继承。)
增加默认模板类型参数,比方说
Foo<T>改为Foo<T, Alloc = alloc<T>>,这会改变name mangling。改变enum的值,把
enum Color { Red = 3 };改为Red = 4。这会造成错位。当然,由于enum自动排列取值,添加enum项也是不安全的(在未尾添加除外)。给class Bar增加数据成员,造成
sizeof(Bar)变大,以及内部数据成员的offset变化,这是不是安全的?通常不是安全的,但也有例外。- 如果客户代码里有
new Bar,那么肯定不安全,因为new的字节数不够装下新Bar对象。相反,如果library通过factory返回Bar*(并通过factory来销毁对象)或者直接返回shared_ptr<Bar>,客户端不需要用到sizeof(Bar),那么可能是安全的。 - 如果客户代码里有
Bar* pBar; pBar->memberA = xx;,那么肯定不安全,因为memberA的新Bar的偏移可能会变。相反,如果只通过成员函数来访问对象的数据成员,客户端不需要用到data member的offsets,那么可能是安全的。 - 如果客户调用
pBar->setMemberA(xx);,而Bar::setMemberA()是个inline function,那么肯定不安全,因为偏移量已经被inline到客户的二进制代码里了。如果setMemberA()是outline function,其实现位于shared library中,会随着Bar的更新而更新,那么可能是安全的。
- 如果客户代码里有
那么只使用header-only的库文件是不是安全呢?不一定。如果你的程序用了boost 1.36.0,而你依赖的某个library在编译的时候用的是1.33.1,那么你的程序和这个library就不能正常工作。因为1.36.0和1.33.1的
boost::function的模板参数类型的个数不一样,后者多了一个allocator。
这里有一份黑名单,列在这里的肯定是二进制不兼容的,没有列出的也可能是二进制不兼容的,见KDE的文档。
2.3 哪些做法多半是安全的
前面我说“不能轻易修改”,暗示有些改动多半是安全的,这里有一份白名单,欢迎添加更多内容。
只要库改动不影响现有的可执行文件的二进制代码的正确性,那么就是安全的,我们可以先部署新的库,让现有的二进制程序受益。
- 增加新的class。
- 增加non-virtual成员函数或static成员函数。
- 修改数据成员的名称,因为生产的二进制代码是按偏移量来访问的。当然,这会造成源码级的不兼容。
2.4 反面教材:COM
在C++中以虚函数作为接口基本上就跟二进制兼容性说“bye-bye”了。具体地说,以只包含虚函数的class(称为interface class)作为程序库的接口,这样的接口是僵硬的,一旦发布,无法修改。
另外,Windows下,Visual C++编译的时候要选择Release或Debug模式,而且Debug模式编译出来的library通常不能在Release binary中使用(反之亦然),这也是因为两种模式下的CRT二进制不兼容(主要是内存分配方面,Debug有自己的簿记(bookkeeping))。Linux就没有这个麻烦,可以混用。
2.5 解决办法
采用静态链接
这种静态链接不是指使用静态库(.a),而是指完全从源码编译出可执行文件(\(\S10.5.3\))。在分布式系统中,采用静态链接也带来部署上的好处,只要把可执行文件放到机器上就能运行,不用考虑它依赖的libraries。目前muduo就是采用静态链接。
通过动态库的版本管理来控制兼容性
这需要非常小心地检查每次改动的二进制兼容性并做好发布计划,比如1.0.x版本系列之间做到二进制兼容,1.1.x版本系列之间做到二进制兼容,而1.0.x和1.1.x不必二进制兼容。《程序员的自我修养》[LLLI]讲了.so文件的命名与二进制兼容性相关的话题,值得一读。
用pimpl技法,编译器防火墙
在头文件中只暴露non-virtual接口,并且class的大小固定为sizeof(Impl*),这样可以随意更新库文件而不影响可执行文件。具体做法见\(\S11.4\)。当然,这么做又多了一道间接性,可能有一定的性能损失。另见《Exceptional C++》的有关条款和《C++编程规范》[CCS,条款43]。
3. 避免使用虚函数作为库的接口
作为C++动态库的作者,应当避免使用虚函数作为库的接口。这么做会给保持二进制兼容性带来很大麻烦,不得不增加很多不必要的interfaces,最终重蹈COM的覆辙。
本节主要讨论Linux x86/x86-64平台,下面会继续举Windows/COM作为反面教材。本节是s11.2“程序库的二进制兼容性”的延续,在初次发表\(\S11.2\)内容的时候,我原本以为大家都对“以C++虚函数作为接口”的害处达成了共识,因此就写得比较简略,但现在看来情况并非如此,我还得展开谈一谈。
“接口”有广义和狭义之分,本节用中文“接口”表示广义的接口,即一个库的代码界面;用英文interface表示狭义的接口,即只包含virtual function的class,这种class通常没有data member,在Java里有一个专门的关键字interface来表示它。
3.1 C++程序库的作者的生存环境
假设你是一个shared library的维护者,你的library被公司另外的两三个团队使用了。你发现了一个安全漏洞,或者某个会导致crash的bug需要紧急修复,那么你修复之后,能不能直接部署library的二进制文件?有没有破坏二进制兼容性?会不会破坏别人团队已经编译好的投入生产环境的可执行文件?是不是要强迫别的团队重新编译链接,把可执行文件也发布新版本?会不会打乱别人的release cycle?这些都是工程开发中经常要遇到的问题。
如果你打算新写一个C++ library,那么通常要做以下几个决策:
- 以什么方式发布?动态库还是静态库?(本节不考虑源代码发布这种情况,这其实和静态库类似。)
- 以什么方式暴露库的接口?可选的做法有:以全局(含namespace级别)函数为接口、以class的non-virtual成员函数为接口、以virtual函数为接口。
Java程序员不需要考虑这么多,直接写class成员函数就行,最多考虑一下要不要给method或class标上final。也不必考虑什么动态库,静态库,都是.jar文件。
在作出上面两个决策之前,我们考虑两个基本假设:
- 代码会有bug,库也不例外。将来可能会发布bug fixes。
- 会有新的功能需求。写代码不是一锤子买卖,总是会有新的需求冒出来,需要程序员往库中增加东西。这是好事情,让程序员不去饭碗。
也就是说,在设计库的时候必须要考虑将来如何升级。如果你的代码第一次发布的时候就已经做到完美,将来不需要任何修改,那么怎么做都行,也就不必继续阅读本节内容了。
基于以上两个基本假设来做决定。第一个决定很好做,如果需要hotfix,那么只能用动态库;否则,在分布式系统中使用静态库更容易部署,这在前面已经谈过。“动态库比静态库节约内存”这种优势在今天看来已不太重要。
下面假定你或者你的老板选择以动态库方式发布,即发布.so或.dll文件,来看看第二个决定怎么做。再说一句,如果你能够以静态库方式发布,后面的麻烦都不会遇到。
3.2 虚函数作为库的接口的两大用途
虚函数作为接口大致有这么两种用法:
- 调用,也就是库提供一个什么功能(比如绘图Graphics),以虚函数为接口方式暴露给客户端代码。客户端代码一般不需要继承这个interface,而是直接调用其member function。这么做据说是有利于接口和实现分离,我认为纯属多此一举、自欺欺人。
- 回调,也就是事件通知,比如网络库的“连接建立”、“数据到达”、“连接断开”等等。客户端代码一般会继承这个interface,然后把对象实体注册到库里面,等库来回调自己。一般来说客户端不会自己去调用这些member function,除非是为了写单元测试模拟库的行为。
- 混合,一个class既可以被客户端代码继承用作回调,又可以被客户端直接调用。说实话我没看出这么做的好处,但实际中某些面向对象的C++库就是这么设计的。
对于“回调”方式,现代C++有更好的做法,即boost::function+boost::bind。muduo的回调即采用这种新方法(\(\S11.5\))。以下不考虑以虚函数为回调的过时做法。
对于“调用”方式,这里举一个虚构的图形库来说明问题。这个库的功能是画线、画矩形、画圆弧:
1 | |
这里略去了很多与本文主题无关的细节,比如Graphics的构造与析构、draw*()函数应该是public、Graphics应该不允许复制,还比如Graphics可能会用pure virtual functions等等,这些都不影响本文的讨论。
这个Graphics库的使用很简单,客户端起来是这个样子。
1 | |
似乎一切都很好,阳光明媚,符合“面向对象的原则”,但是一旦考虑升级,前景立刻变得昏暗。
3.3 虚函数作为接口的弊端
以虚函数作为接口在二进制兼容性方面有本质困难:“一旦发布,不能修改。”
假如我需要给Graphics增加几个绘图函数,同时保持二进制兼容性。这几个新函数的坐标以浮点数表示,我理想中的新接口是:
1 | |
受C++二进制兼容性方面的限制,我们不能这么做。其本质问题在于C++以vtable[offset]方式实现虚函数调用,而offset又是根据虚函数声明的位置隐式确定的,这造成了脆弱性。我增加了drawLine(double x0, double y0, double x1, double y1),造成vtable的排列发生了变化,现有的二进制可执行文件无法再用旧的offset调用到正确的函数。
怎么办呢?有一种危险且丑陋的做法,即把新的虚函数放到interface的末尾:
1 | |
这么做很丑陋,因为新的drawLine(double x0, double y0, double x1, double y1)函数没有和原来的drawLine()函数得在一起,造成了阅读上的不便。这么做同时很危险,因为Graphics如果被继承,那么新增虚函数会改变派生类中的vtable
offset变化,同样不是二进制兼容的。
另外有两种似乎安全的做法,这也是COM采用的办法:
- 通过链式继承来扩展现有的interface,例如从Graphics派生出Graphics2。
1 | |
将来如果继续增加功能,那么还会有class Graphics3 : public
Graphics2以及class Graphics4 : public
Graphics3等等。这么做和前面的做法一样丑陋,因为新的drawLine(double x0, double y0, double x1, double y1)函数位于派生Graphics2
interface中,没有和原来的drawLine()函数待在一起,造成了割裂。
- 通过多重继承来扩展现有的interface,例如定义一个与Graphics class有同样成员的Graphics2,再让实现同时继承这两个interface。
1 | |
这种带版本的interface的做法在COM使用者的眼中看起来是很正常的(比如IXMLDOMDocument、IXMLDOMDocument2、IXMLDOMDocument3,文比如ITaskbarList、ITaskbarList2、ITaskbarList3、ITaskbarList4等等),这解决了二进制兼容性的问题,客户端源代码也不受影响。
在我看来带版本的interface实在是很丑陋,因为每次改动都引入了新的interface class,会造成日后客户端代码难以管理。比如,如果新版应用程序的代码使用了Graphics3的功能,要不要把现有代码中出现的Graphics2都替换掉?
- 如果不替换,一个程序同时依赖多个版本的Graphics,一直背着历史包袱。依赖的Graphics版本越积越多,将来如何管理得过来?
- 如果要替换,为什么不相干的代码(现有的运行得好好的使用Graphics2的代码)也会因为别处用到了Graphics3而被修改?
这种两难境地纯粹是“以函数为库的接口”造成的。如果我们能直接原地扩充class Graphics,就不会有这些麻烦事,见s11.4“动态库接口的推荐做法”。
3.4 假如Linux系统调用以COM接口方式实现
或许上面这个Graphics的例子太简单,没有让“以虚函数为接口”的缺点充分暴露出来,下面让我们看一个真实的案例:Linux Kernel。
Linux kernel从0.01的67个系统调用发展到2.6.37的340个系统调用,kernel interface一直在扩充,而且保持良好的兼容性,它保持兼容性的办法很土,就是给每个system call赋予一个终身不变的数字代号,等于把虚函数表的排列固定下来。打开脚注中的两个链接,你就能看到fork(在Linux 0.01和Linux 2.6.37里的代号都是2。(系统调用的编号跟硬件平台有关,这里我们看的是x86 32-bit平台。)
试想假如Linus当初选择用COM接口的链式继承风格来描述,将会是怎样一种壮观的景象?为了避免扰乱视线,请移步观看近百层继承的代码。
不要误认为“接口一旦发布就不能更改”是天经地义的,那不过是“以C++虚函数为接口”的固有弊端,如果跳出这个框框去思考,其实C++库的接口很容易做得更好。为什么不能改?还不是因为用了C++虚函数作为接口。Java的interface可以添加新函数,C语言的库也可以添加新的全局函数,C++class也可以添加新non-virtual成员函数和namespace级别的non-member函数,这些都不需要继承出新interface就能扩充原有接口。偏偏COM的interface不能原地扩充,只能通过继承来workaround,产生一堆带版本的interfaces。有人说COM是二进制兼容性的正面例子,某深不以为然。COM确实以一种最丑陋的方式做到了“二进制兼容”。脆弱和僵硬就是以C++虚函数为接口的宿命。
相反,Liux系统调用的编号以编译期常数方式固定下来,万年不变,轻而易举地解决了这个问题。在其他面向对象语言(Java/C#)中,我也没有见过每改动一次就给interface递增版本号的诡异做法。还是应了《The Zen of Python》中的那句话:“Explicit is better than implicit,Flat is better than nested."
3.5 Java是如何应对的
Java实际上把C/C++的linking这一步骤推迟到class loading的时候来做。就不存在“不能增加虚函数,“不能修改data member”等问题。在Java中用面向interface编程远比C++更通用和自然,也没有上面提到的“僵硬的接口”问题。
4. 动态库接口的推荐做法
取决于动态库的使用范围,有两类做法。
其一,如果动态库的使用范围比较窄,比如本团队内部的两三个程序在用,用户都是受控的,要发布新版本也比较容易协调,那么不用太费事,只要做好发布的版本管理就行了。再在可执行文件中使用rpath把库的完整路径确定下来。
比如现在Graphics库发布了1.1.0和1.2.0两个版本,这两个版本可以不必是二进制兼容的。用户的代码从1.1.0升级到1.2.0的时候要重新编译一下,反正他们要用新功能都是要重新编译代码的。如果要原地打补丁,那么1.1.1应该和1.1.0二进制兼容,而1.2.1应该和1.2.0兼容。如果要加入新的功能,而新的功能与1.2.0不兼容,那么应该发布到1.3.0版本。
为了便于检查二进制兼容性,可考虑把库的代码的暴露情况分辨清楚。muduo的头文件和class就有意识地分为用户可见和用户不可见两部分(s6.3)。对于用户可见的部分,升级时要注意二进制兼容性,选用合理的版本号:对于用户不可见的部分,在升级库的时候就不必在意。另外muduo本身设计来是以源文件方式发布的,在二进制兼容性方面没有做太多的考虑。
其二,如果库的使用范围很广,用户很多,各家的release cycle不尽相同,那么推荐pimpl技法[CCS,条款43],并考虑多采用non-member non-friend function。
- 暴露的接口里边不要有虚函数,要显式声明构造函数、析构函数,并且不能inline,原因见\(\S10.3.2\)。另外sizeof(Graphics) == sizeof(Graphics::Impl*)。
1 | |
- 在库的实现中把调用转发(forward)给实现Graphics::Impl,这部分代码位于.so/.dll中,随库的升级一起变化。
1 | |
- 如果要加入新的功能,不必通过继承来扩展,可以原地修改,且很容易保持二进制兼容性。先动头文件:
1 | |
然后在实现文件里增加forward,这么做不会破坏二进制兼容性,因为增加non-virtual函数不影响现有的可执行文件。
1 | |
采用pimpl多了一道explicit forward的手续,带来的好处是可扩展性与二进制兼容性,这通常是划算的。pimpl扮演了编译器防火墙的作用。
pimpl不仅C++语言可以用,C语言的库同样可以用,一样带来二进制兼容性的好处,比如libevent2中的struct event_base是个opaque pointer,客户端看不到其成员,都是通过libevent的函数和它打交道,这样库的版本升级比较容易做到二进制兼容。
为什么non-virtual函数比virtual函数更健壮?因为virtual function是bind-by-vtable-offset,而non-virtual function是bind-by-name。加载器(loader)会在程序启动时做决议(resolution),通过mangled name把可执行文件和动态库链接到一起。就像使用Internet域名比使用IP地址更能适应变化一样。
万一要跨语言怎么办?很简单,暴露C语言的接口。Java有JNI可以调用C语言的代码;Python/Perl/Ruby等的解释器都是C语言编写的,使用C函数也不在话下。C函数是Linux下的能接口。
本节只谈了使用class为接口,其实用free function有时候更好(比如muduo/base/Timestamp.h除了定义class Timestamp外,还定义了muduo::timeDifference()等free function),这也是C++比Java等纯面向对象语言优越的地方。
5. 以boost::function和boost::bind取代虚函数
本节的中心思想是“面向对象的继承就像一条贼船,上去就下不来了”,而借助boost::function和boost::bind,大多数情况下,你都不用上“贼”。
boost::function和boost::bind已经纳入了std::tr1,这或许是C++11最值得期待的功能,它将彻底改变C++库的设计方式,以及应用程序的编写方式。
Scott Meyers的[EC3,条款35]提到了以boost::function和boost::bind取代虚函数的做法,另见孟岩的《function/bind的救赎(上)》、《回复几个问题》中的“四个半抽象”,这里谈谈我自己使用的感受。
我对面向对象的“继承”和“多态”的态度是能不用就不用,因为很难纠正错误。如果有一棵类型继承树(class hierarchy),人们在一开始设计时就得考虑各个class在树上的位置。随着时间的推移,原来正确的决定有可能变成错误的。但是更正这个错误的代价可能很高。要想把这个class在继承树上从一个节点挪到另一个节点,可能要触及所有用到这个class的客户代码,所有用到其各层基类的客户代码,以及从这个class派生出来的全部class的代码。简直是牵一发而动全身,在C++缺乏良好重构工具的语言下,有时候只好保留错误,用些wrapper或者adapter来掩盖之。久而久之,设计越来越烂,最后只好推倒重来。解决办法之一就是不采用基于继承的设计,而是写一些容易使用也容易修改的具体类。
总之,继承和虚函数是万恶之源,这条“贼船”上去就不容易下来。不过还好,在C++里我们有别的办法:以boost::function和boost::bind取代虚函数。
用“继承树”这种方式来建模,确实是基于概念分类的思想。“分类”似乎是西方哲学一早就有的思想,影响深远,这种思想估计可以上溯到古希腊时期。
- 比如电影,同以分为科幻片、爱情片、伦理片、战争片、灾难片、恐怖片等等。
- 比如生物,按小学知识可以分为动物和植物,动物又可以分为有脊椎动物和无脊椎动物,有脊椎动物又分为鱼类、两栖类、爬行类、鸟类和哺乳类等。
- 又比如技术书籍分为电子类、通信类、计算机类等等,计算机书籍又可分为编程语言、操作系统、数据结构、数据库、网络技术等等。
这种分类法或许是早期面向对象方法的模仿对象。这种思考方式的本质困难在于:某些物体很难准确分类,似乎有不止一个分类适合它。而且不同的人看法可能不同,比如一部科幻悬疑片到底科幻的成分重还是悬疑的成分重,到底该归入哪一类。
在缩程方面,情况更糟,因为这个“物体x”是变化的,一开始分入A类可能是合理的(x "is-a" A),随着功能演化,分入B类或许更合适(x is more like a B),但是这种改动对现有代码的代价已经太高了(特别是对C++)。
在传统的面向对象语言中,可以用继承多个interfaces来缓解分错类的代价,使得一物多用。但是某些语言限制了基类只能有一个,在新增类型时可能会遇到麻烦,见星巴克卖豆浆奶茶的例子。
现代编程语言这一步走得更远,Ruby的duck typing和Google Go的无继承都可以视作以tag取代分类(层次化的类型)的代表。一个object只要提供了相应的operations,就能当做某种东西来用,不需要显式地继承或实现某个接口。这确实是进步。
对于C++的四种范式,我现在基本只把它当better C和data abstraction来用。OO和GP可以在非常小的范围内使用,只要暴露的接口是object-based(甚至global function)就行。
以上谈了设计层面,再来说一说实现层面。
在传统的C++程序中,事件回调是通过虚函数进行的。网络库往往会定义一个或几个抽象基类(Handler class),其中声明了一些(纯)虚函数,如onConnect()、onDisconnect、onMessage()、onTimer()等等。使用者需要继承这些基类,并覆写(override)这些虚函数,以获得事件回调通知。由于C++的动态绑定只能通过指针和引用实现,使用者必须把派生类(MyHandler)对象的指针或引用隐式转换为基类(Handler)的指针或引用,再注册到网络库中。MyHandler对象通常是动态创建的位于堆上,用完后需要delete。网络库调用基类的虚函数,通过动态绑定机制实际调用的是用户在派生类中override的虚函数,这也是各种OO framework的通行做法。
这种方式在Java这种纯面向对象语言中是正当做法。但是在C++这种非GC语言中,使用虚函数作为事件回调接口有本质困难,即如何管理派生类对象的生命期。
在这种接口风格中,MyHandler对象的所有权和生命期很模糊,到底谁(用户还是网络库)有权力释放它呢?有的网络库甚至出现了delete this;这种代码,让人捏一把汗:如何才能保证此刻程序的其他地方没有保存着这个即将销毁的对象的指针呢?
另外,如果网络库需要自己创建MyHandler对象(比方说需要为每个TCP连接创建一个MyHandler对象),那么就得定义另外一个抽象基类HandlerFactory,用户要从它派生出MyHandlerFactory,再把后者的指针或引用注册到网络库中。以上这些都
是面向对象编程的常规思路,或许大家已经习以为常。
在现代C++中(指2005年TR1之后,不是最新的C++11),事件回调有了新的推荐做法,即boost::function+boost::bind(即std::tr1::function+std::tr1::bind,也是最新C++11中的std::function+std::bind),这种方式的一个明显优点是不必担心对象的生存期。muduo正是用boost::function来表示事件回调的:包括TCP网络编程的三个半IO事件和定时器事件等。用户代码可以传入签名相同的全局函数,也可以借助boost::bind把对象的成员函数传给网络库作为事件回调的接受方。这种接口方式对用户代码的class类型没有限制(不必从特定的基类派生),对成员函数名也没有限制,只对函数签名有部分限制。这样自然也解决了空悬指针的难题,因为传给网络库的都是具有值语义的boost::function对象。从这个意义上说,muduo不是一个面向对象的库,而是一个基于对象的库。因为muduo暴露的接口都是一个个的具体类,完全没有虚函数(无论是调用还是回调)。
Java 8也有新的Closure语法,C#从一诞生就有delegate。
5.1 基本用途
boost::function就像C#里的delegate,可以指向任何函数,包括成员函数。当用bind把某个成员函数绑到某个对象上时,我们得到了一个closure(闭包)。例如:
1 | |
1 | |
如果没有boost::bind,那么boost::function就什么都不是;而有了bind,“同一个类的不同对象可以delegate给不同的实现,从而实现不同的行为”(孟岩),简直就无敌了。
5.2 对程序库的影响
程序库的设计不应该给使用者带来不必要的限制(耦合),而继承是第二强的一种耦合(最强耦合的是全局变量)。如果一个程序库限制其使用者必须从某个class派生,那么我觉得这是一个糟糕的设计。不巧的是,目前不少C++程序库就是这么做的。
例1:线程库
常规OO设计写一个Thread base class,含有(纯)虚函数Thread::run,然后应用程序派生一个derived class,覆写run()。程序里的每一种线程对应一个Thread的派生类。例如Java的Thread class可以这么用。
缺点:如果一个class的三个method需要在三个不同的线程中执行,就得写helper class(es)并玩一些OO把戏。
基于boost::function的设计令Thread是一个具体类,其构造函数接受ThreadCallback对象。应用程序只需提供一个能转换为ThreadCallback的对象(可以是函数),即可创建一个Thread实体,然后调用Thread::start即可。Java的Thread也可以这么用,传入一个Runnable对象。C#的Thread只支持这一种用法,构造函数的参数是delegate ThreadStart。boost::thread也只支持这种用法。
1 | |
使用方式:
1 | |
例2:网络库
以boost::function作为桥梁,NetServer class对其使用者没有任何类型上的限制,只对成员函数的参数和返回类型有限制。使用者EchoService也完全不知道NetServer的存在,只要在main()里把两者装配到一起,程序就跑起来了。
1 | |
5.3 对面向对象程序设计的影响
一直以来,我对面向对象都有一种厌恶感,叠床架屋,绕来绕去的,一拳拳打在棉花上,不解决实际问题。面向对象的三要素是封装、继承和多态。我认为封装是根本的,继承和多态则是可有可无的。用class来表示concept,这是根本的;至于继承和多态,其耦合性太强,往往不划算。
继承和多态不仅规定了函数的名称、参数、返回类型,还规定了类的继承关系。在现代的OO编程语言里,借助反射和attribute/annotation,已经大大放宽了限制。举例来说,JUnit 3.x是用反射,找出派生类里的名字符合void test*()的函数来执行的,这里就没继承什么事,只是对函数的名称有部分限制(继承是全面限制,一字不差)。至于JUnit 4.x和NUnit 2.x则更进一步,以annotation/attribute来标明test case,更没继承什么事了。
我的猜测是,当初提出面向对象的时候,closure还没有一个通用的实现,所以它没能算作基本的抽象工具之一。现在既然closure已经这么方便了,或许我们应该重新审视面向对象设计,至少不要那么滥用继承。
自从找到了boost::function+boost::bind这对“神兵利器”,不用再考虑class之间的继承关系,只需要基于对象的设计(object-based),拳拳到肉,程序写起来顿时顺手了很多。
对面向对象设计模式的影响
既然虚函数能用closure代替,那么很多OO设计模式,尤其是行为模式,就失去了存在的必要。另外,既然没有继承体系,那么很多创建型模式似乎也没啥用了(比如Factory Method可以用boost::function<Base*()>替代)。
最明显的是Strategy,不用累赘的Strategy基类和ConcreteStrategyA, ConcreteStrategyB等派生类,一个boost::function成员就能解决问题。另外一个例子是Command模式,有了boost::function,函数调用可以直接变成对象,似乎就没Command什么事了。同样的道理,Template Method可以不必使用基类与继承,只要传入几个boost::function对象,在原来调用虚函数的地方换成调用boost::function对象就能解决问题。
在《设计模式》这本书中提到了23个模式,在我看来其更多的是弥补了C++这种静态类型语言在动态性方面的不足。在动态语言中,由于语言内置了一等公民的类型和函数,这使得很多模式失去了存在的必要。或许它们解决了面向对象中的常见问题,不过要是我的程序连面向对象(指继承和多态)都不用,那似乎也不用考虑面向对象设计模式了。
或许基于closure的编程将作为一种新的编程范式(paradigm)而流行起来。
依赖注入与单元测试
前面的EchoService可算是依赖注入的例子。EchoService需要一个什么东西来发送消息,它对这个“东西”的要求只是函数原型满足SendMessageCallback,而不关心数据到底发到网络上还是发到控制台。在正常使用的时候,数据应该发给网络;而在做单元测试的时候,数据应该发给某个Datasink。
按照面向对象的思路,先写一个AbstractDataSink interface,包含sendMessage()这个虚函数,然后派生出两个class:NetDataSink和MockDataSink,前面那个正常使用,后面那个单元测试用。EchoService的构造函数应该以AbstractDataSink*为参数,这样就实现了所谓的接口与实现分离。
我认为这么做纯粹是多此一举,因为直接传入一个SendMessageCallback对象就能解决问题。在单元测试的时候,可以boost::bind到MockServer上,或某个全局函数上,完全不用继承和虚函数,也不会影响现有的设计。
什么时候使用继承
如果是指OO中的public继承,即为了接口与实现分离,那么我只会在派生类的数目和功能完全确定的情况下使用。换句话说,不为将来的扩展考虑,这时候面向对象或许是一种不错的描述方法。一旦要考虑扩展,什么办法都没用,还不如把程序写简单点,将来好大改或重写。
如果是功能继承,那么我会考虑继承boost::noncopyable或boost::enable_shared_from_this,S1.11讲到了enable_shared_from_this在实现多线程安全的对象回调时的妙用。
例如,IO multiplexing在不同的操作系统下有不同的推荐实现,最通用的select()、POSIX的poll()、Linux的epoll()、FreeBSD的kqueue()等,数目固定,功能也完全确定,不用考虑扩展。那么设计一个NetLoop base class加若干具体classes就是不错的解决办法。换句话说,用多态来代替switch-case以达到简化代码的目的。
基于接口的设计
这个问题来自那个经典的讨论:不会飞的企鹅(Penguin)究竟应不应该继承自鸟(Bird),如果Bird定义了virtual function fly()的话。讨论的结果是,把具体的行为提出来,作为interface,比如Flyable(能飞的),Runnable(能跑的),然后让企鹅实现Runnable,麻雀实现Flyable和Runnable。(其实麻雀只能双脚跳,不能跑,这里不作深究。)
进一步的讨论表明,interface的粒度应足够小,或许包含一个method就够了,那么interface实际上退化成了给类型打的标签(tag)。在这种情况下,完全可以使用boost::function来代替,比如:
1 | |
6. iostream的用途与局限
本节主要考虑x86 Linux平台,不考虑跨平台的可移植性,也不考虑国际化(i18n),但是要考虑32-bit和64-bit的兼容性。本节以stdio指代C语言的scanf/printf系列格式化输入输出函数。本节提及的“C语言”(包括库函数和线程安全性),指的是Linux下gcc+glibc这一套编译器和库的具体实现,也可以认为是符合POSIX.1-2001的实现。本节要注意区分“编程初学者”和“C++初学者”,二者含义不同。
C++ iostream的主要作用是让初学者有一个方便的命令行输入输出试验环境,在真实的项目中很少用到iostream,因此不必把精力花在深究iostream的格式化与manipulator(格式操控符)上。iostream的设计初衷是提供一个可扩展的类型安全的IO机制,但是后来莫名其妙地加入了locale和facet等累赘。其整个设计复杂不堪,多重+虚拟继承的结构也很“巴洛克”,性能方面几无亮点。iostream在实际项目中的用处非常有限,为此投入过多的学习精力实在不值。
6.1 stdio格式化输入输出的缺点
对编程初学者不友好
看看下面这段简单的输入输出代码,这是C语言教学的基本示例。
1
2
3
4
5
6
7
8
9
10#include <stdio.h>
int main() {
int i;
short s;
float f;
double d;
char name[80];
scanf("%d%hd%f%lf%s", &i, &s, &f, &d, name);
printf("%d %hd %f %lf %s\n", i, s, f, d, name);
}注意到其中输入和输出用的格式字符串不一样。输入short要用%hd,输出用%d;输入double要用%lf,输出用%f。
输入的参数不统一。对于i、s、f、d等变量,在传入scanf()的时候要取地址(&);而对于字符数组name,则不用取地址。读者可以试一试如何用几句话向刚开始学编程的初学者解释上面两条背后的原因(涉及传递函数不定参数时的类型转换、函数调用栈的内存布局、指针的意义、字符数组退化为字符指针等等)。如果一开始解释不清,只好告诉初学者“这是规定”,弄得人一头雾水。
缓冲区溢出的危险。上面的例子在读入name的时候没有指定大小,这是用C语言编程的安全漏洞的主要来源。应该在一开始就强调正确的做法,避免养成错误的习惯。
正确而安全的做法如下所示:
1
2
3
4
5
6
7
8int main() {
const int max_name = 80;
char name[max_name];
char fmt[10];
sprintf(fmt, "%%%ds", max_name - 1);
scanf(fmt, name);
printf("%s\n", name);
}这个动态构造格式化字符串的做法恐怕更难向初学者解释。
安全性(security)
C语言的安全性问题近十几年来引起了广泛的注意,C99增加了snprintf()等能够指定输出缓冲区大小的函数,输出方面的安全性问题已经得到解决;输入方面似乎没有太大进展,还要靠程序员自己动手。
考虑一个简单的编程任务:从文件或标准输入读入一行字符串,行的长度不确定。我发现竟然没有哪个C语言标准库函数能完成这个任务,除非自己动手。
- 首先,gets()是错误的,因为不能指定缓冲区的长度。
- 其次,fgets()也有问题。它能指定缓冲区的长度,所以是安全的。但是程序必须预设一个长度的最大值,这不满足题目要求“行的长度不确定”。另外,程序无法判断fgets()到底读了多少个字节。为什么?考虑一个文件的内容是9个字节的字符串“Chen\000Shuo”,注意中间出现了"\0"字符,如果用fgets来读取,客户端如何知道"\000Shuo"也是输入的一部分?毕竟strlen只返回4,而且整个字符串里没有""字符。
- 最后,可以用glibc定义的getline(3)函数来读取不定长的“行”。这个函数能正确处理各种情况,不过它返回的是malloc分配的内存,要求调用端自己已free()。
类型安全(type-safety)
如果printf()的整数参数类型是int、long等内置类型,那么printf()的格式化字符串很容易写。但是如果参数类型是系统头文件里typedef的类型呢?
如果你想在程序中用printf()来打印日志,你能一眼看出下面这些类型该用"%d"、"%ld"、"%lld"中的哪一个来输出吗?你的选择是否同时兼容32-bit和64-bit平台?
- clock_t。这是clock(3)的返回类型。
- dev_t。这是mknod(3)的参数类型。
- in_addr_t、in_port_t。这是struct sockaddr_in的成员类型。
- nfds_t。这是poll(2)的参数类型。
- off_t。这是lseek(2)的参数类型,麻烦的是,这个类型与宏定义_FILE_OFFSET_BITS有关。
- pid_t、uid_t、gid_t。这是getpid(2)/getuid(2)/getgid(2)的返回类型。
- ptrdiff_t。printf()专门定义了"t"前缀来支持这一类型(即使用"%td")。
- size_t、ssize_t。这两个类型到处都在用。printf()为此专门定义了"z"前缀来支持这两个类型(即使用"%zu"或"%zd"来打印)。
- socklen_t。这是bind(2)和connect(2)的参数类型。
- time_t。这是time(2)的返回类型,也是gettimeofday(2)和clock_gettime(2)的结构体参数的成员类型。
如果在C程序中正确打印以上类型的整数,恐怕要费一番脑筋。《The Linux Programming Interface》的作者建议(3.6.2节)先统一转换为long类型,再用"%ld"来打印;对于某些类型仍然需要特殊处理,比如off_t的类型可能是long long。
另外,int64_t在32-bit和64-bit平台上是不同的类型,为此,如果程序要打印int64_t变量,需要包含<inttypes.h>头文件,并且使用PRId64宏:
1 | |
muduo的Timestamp class使用了PRId64。Google C++编码规范也提到了64-bit兼容性。
这些问题在C++里都不存在,在这方面iostream是个进步。
Cstdio在类型安全方面原本还有一个缺点,即格式化字符串与参数类型不匹配会造成难以发现的bug,不过现在的编译器已经能够检测很多这种错误(使用-Wall编译选项):
1 | |
不可扩展
Cstdio的另外一个缺点是无法支持自定义的类型,比如我写了一个Date class,我无法像打印int那样用printf来直接打印Date对象。
1 | |
glibc放宽了这个限制,允许用户调用register_printf_function(3)注册自己的类型。当然,前提是与现有的格式化符不冲突(这其实大大限制了这个功能的用处,现实中也几乎没有人真的去用它)。
性能
Cstdio的性能方面有两个弱点。
- 使用一种little language(现在流行叫DSL)来配置格式。这固然有利于紧凑性和灵活性,但损失了一点点效率。每次打印一个整数都要先解析“%d”字符串,大多数情况下这不是问题,某些场合则需要自己写整数到字符串的转换。
- C locale的负担。locale指的是不同语种对“什么是空白”、“什么是字母”,“什么是小数点”有不同的定义德语中小数点是逗号,不是句点。C语言的printf、scanf、isspace()、isalpha()、ispunct()、strtod()等等函数都和locale有关,而且可以在运行时动态更改locale。就算是程序只使用默认的"C" locale,仍然要为这个灵活性付出代价。
6.2 iostream的设计初衷
iostream的设计初衷包括克服Cstdio的缺点,提供一个高效的可扩展的类型安全的IO机制。“可扩展”有两层意思:一是可以扩展到用户自定义类型,二是通过继承iostream来定义自己的stream。本文把前一种称为“类型可扩展”,把后一种称为“功能可扩展”。
类型可扩展和类型安全
“类型可扩展”和“类型安全”都是通过函数重载来实现的。
iostream对初学者很友好,用iostream重写与前面同样功能的代码:
1 | |
这段代码恐怕比scanf/printf版本容易解释得多,而且没有安全性(security)方面的问题。
我们自己的类型也可以融入iostream,使用起来与built-in类型没有区别。这主要得力于C++可以定义non-member functions/operators。
1 | |
iostream凭借这两点(类型安全和类型可扩展),基本克服了stdio在使用上的不便与不安全。如果iostream止步于此,那它将是一个非常便利的库,可惜它前进了另外一步。
iostream的演变大致可分为三个阶段。第一阶段是Bjarne Stroustrup在CFront 1.0里实现的streams库。这个库符合前述“类型安全、可扩展、高效”等特征,Bjarne发明了用移位操作符(<<和>>)做I/O的办法,istream和ostream都是具体类,也没有manipulator。第二阶段,Jerry Schwarz设计了“经典”iostream,在CFront 2.0中他的设计大部分得以体现。他发明了manipulator,实现手法是以函数指针参数来重载输入输出操作符;他还采用多重继承和虚拟继承手法,设计了我们现在看到的ios菱形继承体系;此外,istream有了基类ios,也有了派生类ifstream和istrstream,ostream也是如此。第三阶段,在C++标准化的过程中,iostream有大幅更新,Nathan Myers设计了Locale/Facet体系,iostream被模板化以适应宽窄两种字符,以及以stringstream替换strstream等。
6.3 iostream与标准库其他组件的交互
“值语义”与“对象语义”
不同于标准库其他class的“值语义(value semantics)”,iostream是“对象语义(object semantics)”,即iostream是non-copyable。这是正确的,因为如果fstream代表一个打开的文件的话,拷贝一个fstream对象意味着什么呢?表示打开了两个文件吗?如果销毁一个fstream对象,它会关闭文件句柄,那么另一个fstream对象副本会因此受影响吗?
iostream禁止拷贝,利用对象的生命期来明确管理资源(如文件),很自然地就避免了这些问题。这就是RAII,一种重要且独特的C++编程手法。
C++同时支持“数据抽象(data abstraction)”和“面向对象编程(object-oriented)”,其实主要就是“值语义”与“对象语义”的区别,这是一个比较大的主题,见11.7。
std::string
iostream可以与std::string配合得很好。但是有一个问题:谁依赖谁?
std::string的operator<<和operator>>是如何声明的?注意operator<<是个二元操作符,它的参数是std::ostream和std::string。<string>头文件在声明这两个operator的时候要不要#include<iostream>?
iostream和std::string都可以单独include来使用,显然iostream头文件里不会定义std::string的<<和>>操作。但是,如果<string>要#include<iostream>,岂不是让string的用户被迫也用了iostream?编译iostream头文件可是相当的慢啊(因为iostream是template,其实现代码都放到了头文件中)。
标准库的解决办法是定义<iosfwd>头文件,其中包含istream和ostream等的前向声明(forward declarations),这样<string>头文件在定义输入输出操作符时就可以不必包含<iostream>,只需要包含简短得多的<iosfwd>,避免引入不必要的依赖。我们自己写程序也可借此学习如何支持可选的功能。
另外值得注意的是,istream::getline成员函数的参数类型是char,因为<istream>没有包含<string>,而我们常用的std::getline()函数是个non-member function,定义在<string>里边。
std::complex
标准库的复数类std::complex的情况比较复杂。<complex>头文件会自动包含<sstream>,后者会包含<istream>和<ostream>,这是个不小的负担。问题是,为什么这么实现?
它的operator>>操作比string复杂得多,如何应对格式不正确的情况?输入字符串不会遇到格式不正确,但是输入一个复数则可能遇到各种问题,比如数字的格式不对等。有谁会真的在产品项目里用operator>>来读入字符方式表示的复数,这样的代码的健壮性如何保证?基于同样的理由,我认为产品代码中应该避免用istream来读取带格式的内容,后面也不再谈istream格式化输入的缺点,它已经落选。
它的operator<<也很奇怪,它不是直接使用参数ostream&os对象来输出,而是先构造ostringstream,输出到该stringstream,再把结果字符串输出到ostream。
简化后的代码如下:
1 | |
注意到ostringstream会用到动态分配内存。也就是说,每输出一个complex对象就会分配释放一次内存,效率堪忧。
根据以上分析,我认为iostream和complex配合得不好,但是它们耦合得更紧密(与string/iostream相比),这可能是个不得已的技术限制吧(complex是class template,其operator<<必须在头文件中定义,而这个定义又用到了ostringstream,不得已包含了sstream的实现)。
如果程序要对complex做IO.从效率和健壮性方面考虑,建议不要使用iostream。
6.4 iostream在使用方面的缺点
在简单使用iostream的时候,它确实比stdio方便,但是深入一点就会发现,二者可说各擅胜场。下面谈一谈iostream在使用方面的缺点。
格式化输出很烦琐
iostream采用manipulator来格式化,如果我想按照2010-04-03的格式输出前面定义的Date class,那么代码要改成:
1 | |
假如用stdio,会简短得多,因为printf采用了一种表达能力较强的小语言来描述输出格式。
1 | |
使用小语言来描述格式还带来了另外一个好处:外部可配置。
外部可配置性
能不能用外部的配置文件来定义程序中日期的格式?在Cstdio中很好办,把格式字符串"%d-%02d-%02d"保存到配置里就行。但是iostream呢?它的格式是写死在代码里的,灵活性大打折扣。
再举个例子,程序的message的多语言化。
1 | |
对于stdio,要让这段程序支持中文的话,把代码中的"My name is ...",替换为“我叫%1s,今年%2$d岁。”即可。也可以把这段提示语做成资源文件,在运行时读入。而对于iostream,恐怕没有这么方便,因为代码是支离破碎的。
Cstdio的格式化字符串体现了重要的“数据就是代码”的思想,这种“数据”与“代码”之间的相互转换是程序灵活性的根源,远比OO更为灵活。
stream的状态
如果我想用十六进制方式输出一个整数x,那么可以用hex操控符,但是这会改变ostream的状态。比如说
1 | |
这段代码会把123也按照十六进制方式输出,这恐怕不是我们想要的。
再举一个例子,setprecision()也会造成持续影响:
1 | |
输出是:
1 | |
可见代码中的setprecision()影响了后续输出的精度。注意setw()不会造成影响,它只对下一个输出有效。
这说明,如果使用manipulator来控制格式,需要时刻小心以防影响了后续代码;而使用Cstdio就没有这个问题,它是“上下文无关的”。
知识的通用性
在C语言之外,有其他很多语言也支持printf风格的格式化,例如Java、Perl、Ruby等等。学会printf()的格式化方法,这个知识还可以用到其他语言中。
但是C++ iostream“只此一家,别无分店”。反正都是格式化输出,学习stdio投资回报率更高。
线程安全与原子性
iostream的另外一个问题是线程安全性。POSIX.1-2001明确要求stdio函数是线程安全的,而且还提供了flockfile(3)/funlockfile(3)之类的函数来明确控制FILE*的加锁与解锁。
iostream在线程安全方面没有保证,就算单个operator<<是线程安全的,也不能保证原子性。因为cout << a << b;是两次函数调用,相当于cout.operator<<(a).operator<<(b)。两次调用中间可能会被打断进行上下文切换,造成输出内容不连续,插入了其他线程打印的字符。而fprintf(stdout, "%s%d", a, b);是一次函数调用,而且是线程安全的,打印的内容不会受其他线程影响。因此,iostream并不适合在多线程程序中做logging。
6.5 iostream的局限
根据以上分析,我们可以归纳iostream的局限:
- 输入方面,istream不适合输入带格式的数据,因为“纠错”能力不强,进一步的分析请见孟岩写的《契约式设计的一个反面案例》,孟岩说“复杂的设计必然带来复杂的使用规则,而面对复杂的使用规则,用户是可以投票的,那就是你做你的,我不用!”可谓鞭辟入里。如果要用istream,我推荐的做法是用std::getline()读入一行数据到std::string,然后用正则表达式来判断内容正误,并做分组,最后用strtod()/strtol()之类的函数做类型转换。这样似乎更容易写出健壮的程序。
- 输出方面,ostream的格式化输出非常烦琐,而且写死在代码里,不如stdio的小语言那么灵活通用。建议只用作简单的无格式输出。
- log方面,由于ostream没有办法在多线程程序中保证一行输出的完整性,建议不要直接用它来写log。如果是简单的单线程程序,输出数据量较少的情况下可以情使用。产品代码应该用成熟的logging库,见第5章。
- in-memory格式化方面,由于ostringstream会动态分配内存,它不适合性能要求较高的场合。
- 文件IO方面,如果用作文本文件的输入或输出,fstream有上述的缺点;如果用作二进制数据的输入输出,那么自己简单封装一个File class似乎更好用,也不必为用不到的功能付出代价(后文还有具体例子)。ifstream的一个用处是在程序启动时读入简单的文本配置文件。如果配置文件是其他文本格式的(XML或JSON),那么用相应的库来读,也用不到ifstream。
- 性能方面,iostream没有兑现“高效性”诺言。iostream在某些场合比stdio快,在某些场合比stdio慢,对于性能要求较高的场合,我们应该自己实现字符串转换(见后文的代码与测试)。
既然有这么多局限,iostream在实际项目中的应用就大为受限了,在这上面投入太多的精力实在不值得。说实话,我没有见过哪个C++产品代码使用iostream来作为输入输出设施。Google的C++编程规范也对stream的使用做了明确的限制。
6.6 iostream在设计方面的缺点
iostream的设计有相当多的WTFs,stackoverflow有人抱怨说:“If you had to judge by today's software engineering standards, would C++'s IOStreams still be considered well-designed?”
面向对象的设计
iostream是个面向对象的IO类库,本节简单介绍它的继承体系。对iostream略有了解的人会知道它用了多重继承和虚拟继承,简单地画个类图如下(见图11-1):
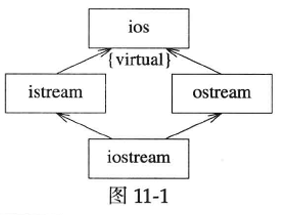
这是典型的菱形继承。
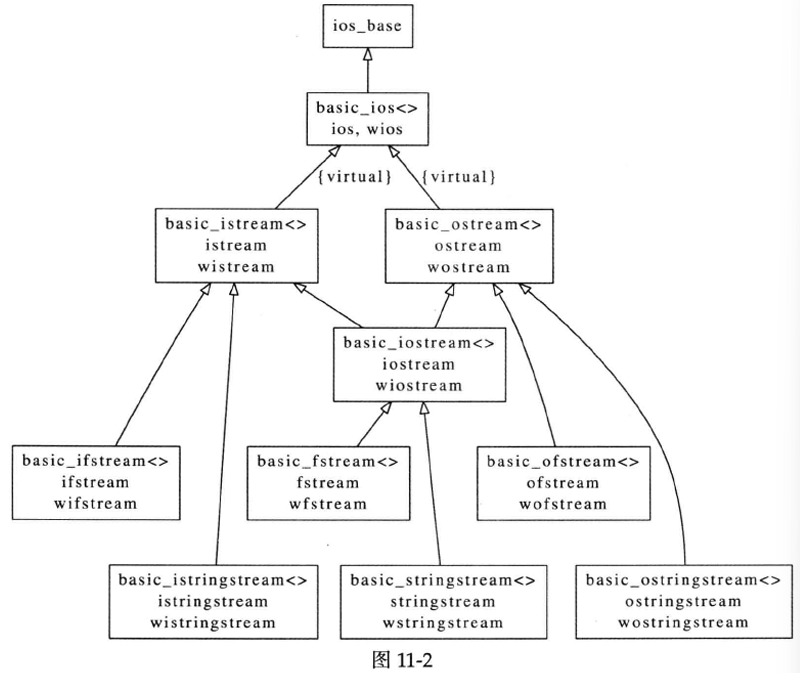
如果加深一点了解,会发现iostream现在是模板化的,同时支持窄字符和宽字符。图11-2是现在的继承体系,同时画出了fstream(s)和stringstream(s)。图11-2中方框的第二三行是模板的具现化类型,即我们代码里常用的具体类型(通过typedef定义)。这个继承体系揉合了面向对象与泛型编程,但可惜它两方面都不讨好。
再进一步加深了解,发现还有一个平行的streambuf继承体系(见图11-3):
fstream和stringstream的主要区别在于使用了不同的streambuf派生类型。
再把这两个继承体系画到一幅图里,如图11-4所示。
注意到basic_ios持有了streambuf的指针;而fstream(s)和stringstream(s)则分别包含filebuf和stringbuf的对象。看上去有点像Bridge模式。
看了这样“巴洛克”的设计,有没有人还打算在自己的项目中通过继承iostream来实现自己的stream,以实现功能扩展呢?
面向对象方面的设计缺陷
本节我们分析一下iostream的设计违反了哪些OO准则。
我们知道,面向对象中的public继承需要满足Liskov替换原则,继承非为复用,乃为被复用。在程序里需要用到ostream的地方(例如operator<<),我传入ofstream或ostringstream都应该能按预期工作,这就是OO继承强调的“可替换性”,派生类的对象可以替换基类对象,从而被客户端代码operator<<复用。
iostream的继承体系多次违反了Liskov原则,这些地方继承的目的是为了复用基类的代码,图11-5中我把违规的继承关系用虚线标出。
在现有的继承体系中(见图11-5),合理的有:
- ifstream is-a istream
- istringstream is-a istream
- ofstream is-a ostream
- ostringstream is-a ostream
- fstream is-a iostream
- stringstream is-a iostream
我认为不怎么合理的有:
- ios继承ios_base。有没有哪种情况下函数期待ios_base对象,但是客户可以传入一个ios对象替代之?如果没有,这里用public继承是不是违反OO原则?
- istream继承ios。有没有哪种情况下函数期待ios对象,但是客户可以传入一个istream对象替代之?如果没有,这里用public继承是不是违反OO原则?
- ostream继承ios。有没有哪种情况下函数期待ios对象,但是客户可以传入一个ostream对象替代之?如果没有,这里用public继承是不是违反OO原则?
- iostream多重继承istream和ostream。为什么iostream要同时继承两个non-interface class?这是接口继承还是实现继承?是不是可以用组合(composition)来替代?
用组合替换继承之后的体系如图11-6所示。
注意到在新的设计中,只有真正的is-a关系采用了public继承,其他均以组合来代替,组合关系以菱形箭头表示。新的设计没有使用虚拟继承或多重继承。
其中iostream的新实现值得一提,代码结构如下:
1
2
3
4
5
6
7
8class istream;
class ostream;
class iostream {
public:
istream& get_istream();
ostream& get_ostream();
virtual ~iostream();
};
这样一来,在需要iostream对象表现得像istream的地方,调用get_istream()函数返回一个istream的引用;在需要iostream对象表现得像ostream的地方,调用get_ostream()函数返回一个ostream的引用。功能不受影响,而且代码更清晰,istream和ostream也不必使用虚拟继承了。(我非常怀疑iostream class的真正价值,一个东西既可读又可写,说明它是一个sophisticated IO对象,为什么还用这么厚的封装?)
阳春的locale
iostream的故事还不止这些,它还包含一套阳春的locale/facet实现,这套实践中没人用的东西进一步增加了iostream的复杂度,而且不可避免地影响其性能。
Nathan Myers正是其始作俑者。
ostream自身定义的针对整数和浮点数的operator<<成员函数的函数体是:
1 | |
它会调用num_put::put(),后者会去调用num_put::do_put(),而do_put()是个虚函数,没办法inline。iostream在性能方面的不足恐怕部分来自于此。这个虚函数白白浪费了把template的实现放到头文件应得的好处,编译和运行速度都快不起来。这就是我说iostream在泛型方面不讨好的原因。
我没有深入挖掘其中的细节,感兴趣的读者可以移步观看facet的继承体系:
臆造抽象
孟岩评价“iostream最大的缺点是臆造抽象”,我非常赞同他的观点。
这个评价同样适用于Java那一套“叠床架屋”的InputStream、OutputStream、Reader、Writer继承体系,NET也搞了这么一套繁文缛节。
乍看之下,用InputStream表示一个可以“读”的数据流,用OutputStream表示一个可以“写”的数据流,屏蔽底层细节,面向接口编程,“符合面向对象原则”,似乎是一件美妙的事情。但是,真实的世界要残酷得多。
IO是个极度复杂的东西,就拿最常见的memory stream、file stream、socket stream来说,它们之间的差异极大:
- 是单向IO还是双向IO。只读或者只写?还是既可读又可写?
- 顺序访问还是随机访问。可不可以seek?可不可以退回n字节?
- 文本数据还是二进制数据。输入数据格式有误怎么办?如何编写健壮的处理输入的代码?
- 有无缓冲。write 500字节是否能保证完全写入?有没有可能只写入了300字节?余下200字节怎么办?
- 是否阻塞。会不会返回EWOULDBLOCK错误?
- 有哪些出错的情况。这是最难的,memory stream几乎不可能出错,file stream和socket stream的出错情况完全不同。socket stream可能遇到对方断开连接,file stream可能遇到超出磁盘配额。
根据以上列举的初步分析,我不认为有办法设计一个公共的基类把各方面的情况都考虑周全。各种IO设施之间共性太小,差异太大,例外太多。如果硬要用面向对象来建模,基类要么太瘦(只放共性,这个基类包含的interface functions没多大用),要么太肥(把各种IO设施的特性都包含进来,这个基类包含的interface functions很多,但是不是每一个都能调用)。
一个基类设计得好,大家才愿意去继承它。比如Runnable是个很好的抽象,有不计其数的实现。InputStream/OutputStream也好,也有若干个实现(见图11-7)。反观istream/ostream,只有标准库提供的两套默认实现,在项目中极少有人会去继承并扩展它,是不是说明istream/ostream这一套抽象不怎么好使呢?
当然,假如Java有C++那样强大的template机制,图11-7中的继承体系能简化不少。
若要在C语言里解决这个问题,通常的办法是用一个int表示IO对象(file或PIPE或socket),然后配以read()/write()/lseek()/fcntl()等一系列全局函数,程序员自己搭配组合。这个做法我认为比面向对象的方案要简洁高效。
iostream在性能方面没有比stdio高多少,在健壮性方面多半不如stdio,在灵活性方面受制于本身的复杂设计而难以让使用者自行扩展。目前看起来只适合一些简单的、要求不高的应用,但是我们不得不为它的复杂设计付出运行时代的代价,总之,其定位有点不上不下。
在实际的项目中,我们可以提炼出一些简单高效的strip-down版本,在获得便利性的同时避免付出不必要的代价。
6.7 一个300行的memory buffer output stream
我认为以operator<<来输出数据不太适合logging(见第5章),因此写了一个简单的muduo::LogStream class。代码不到300行,完全独立于iostream,位于muduo/base/LogStream.(h,cc)。
这个LogStream做到了类型安全和类型可扩展,效率也较高。它不支持定制格式化、不支持locale/facet、没有继承、buffer也没有继承与虚函数、没有动态分配内存、buffer大小固定。简单地说,适合logging以及简单的字符串转换。这基本上是Bjarne在1984年写的ostream的翻版。
LogStream的接口定义如下:
1 | |
LogStream本身不是线程安全的,它不适合做线程间的共享对象。正确的使用方式是每条log消息构造一个LogStream,用完就扔。LogStream的成本极低,这么做不会有什么性能损失。
整数到字符串的高效转换
muduo::LogStream的整数转换是自己已写的,用的是Matthew Wilson的算法,见12.3“带符号整数的除法与余数”。这个算法比stdio和iostream都要快。
浮点数到字符串的高效转换
目前muduo::LogStream的浮点数格式化采用的是snprintf()。所以从性能上与stdio持平,比ostream快一些。
浮点数到字符串的转换是个复杂的话题,这个领域20年以来没有什么进展(目前的实现大都基于David M. Gay在1990年的工作:《Correctly Rounded Binary-Decimal and Decimal-Binary Conversions》,代码:http://netlib.org/fp/),直到2010年才有突破。
Florian Loitsch发明了新的更快的算法Grisu3,他的论文《Printing floating point numbers quickly and accurately with integers》发表在PLDI2010,代码见Google V8引擎以及http://code.google.com/p/double-conversion/。有兴趣的读者可以阅读这篇博客。
将来muduo::LogStream可能会改用Grisu3算法实现浮点数转换。
性能对比
由于muduo::LogStream抛掉了很多负担,因此可以预见它的性能好于ostringstream和stdio。我做了一个简单的性能测试,结果如表11-1和表11-2所示。表11-1和表11-2中的数字是打印1000000次的用时,以毫秒为单位,越小越好。
表11-1 64-bit测试结果
| snprintf | ostringstream | LogStream | |
|---|---|---|---|
| int | 499 | 363 | 113 |
| double | 2315 | 3835 | 2338 |
| int64_t | 486 | 347 | 145 |
| void* | 419 | 330 | 47 |
表11-2 32-bit测试结果
| snprintf | ostringstream | LogStream | |
|---|---|---|---|
| int | 544 | 453 | 116 |
| double | 2241 | 4030 | 2267 |
| int64_t | 725 | 958 | 654 |
| void* | 690 | 425 | 65 |
从表11-1和表11-2看出,ostringstream有时候比snprintf()快,有时候比它慢,muduo::LogStream比它们两个都快得多(double类型除外)。
泛型编程
其他程序库如何使用LogStream作为输出呢?办法很简单,用模板。
前面我们定义了Date class针对std::ostream的operator<<,只要稍作修改就能同时适用于std::ostream和LogStream。而且Date的头文件不再需要#include <ostream>,降低了耦合。
1 | |
格式化
muduo::LogStream本身不支持格式化,不过我们很容易为它做扩展,定义一个简单的Fmt class就行,而且不影响stream的状态。
1 | |
使用方法:
1 | |
6.8 现实的C++程序如何做文件IO
下面举三个例子,Google Protobuf Compiler,Google leveldb,Kyoto Cabinet。
Google Protobuf Compiler
Google Protobuf是一种高效的网络传输格式,它用一种协议描述语言来定义消息格式,并且自动生成序列化代码。Protobuf Compiler是这种“协议描述语言”的编译器,它读入协议文件.proto,编译生成C++、Java、Python代码。proto文件是个文本文件,然而Protobuf Compiler并没有使用ifstream来读取它,而是使用了自己的FileInputStream来读取文件。
大致代码流程如下:
- ZeroCopyInputStream是一个抽象基类。
- FileInputStream继承并实现了ZeroCopyInputStream。
- Tokenizer是词法分析器,它把proto文件分解为一个个字元(token)。 Tokenizer的构造函数以ZeroCopyInputStream为参数,从该stream读入文本。
- Parser是语法分析器,它把proto文件解析为语法树,以FileDescriptorProto表示。 Parser的构造函数以Tokenizer为参数,从它读入字元。
可见,即使是读取文本文件,C++程序也不一定要用ifstream。
Google leveldb
Google leveldb是一个高效的持久化key-value db。它定义了三个精简的interface用于文件输入输出:
- SequentialFile
- RandomAccessFile
- WritableFile
接口函数如下:
1 | |
leveldb明确区分input和output,并进一步把input分为sequential和random access,然后提炼出了三个简单的接口,每个接口只有屈指可数的几个函数。这几个接口在各个平台下的实现也非常简单明了,一看就懂。
注意这三个接口使用了虚函数,我认为这是正当的,因为一次IO往往伴随着系统调用和context switch,虚函数的开销比起context switch来可以忽略不计。相反,iostream每次operator<<()就调用虚函数,似乎不太明智。
Kyoto Cabinet
Kyoto Cabinet也是一个key-value db,是前几年流行的Tokyo Cabinet的升级版。它采用了与leveldb不同的文件抽象。KC定义了一个File class,同时包含了读写操作,这是一个fat interface。在具体实现方面,它没有使用虚函数,而是采用#ifdef来区分不同的平台,等于把两份独立的代码写到了同一个文件中。
相比之下,Google leveldb的做法更高明一些。
小结
在C++项目中,自己写个File class,把项目用到的文件IO功能简单封装一下(以RAII手法封装FILE*或者file descriptor都可以,视情况而定),通常就能满足需要。记得把拷贝构造和赋值操作符禁用,在析构函数里释放资源,避免泄露内部的handle,这样就能自动避免很多C语言文件操作的常见错误。
如果要用stream方式做logging,可以抛开繁重的iostream,自己写一个简单的LogStream,重载几个operator<<操作符,用起来一样方便;而且可以用stack buffer,轻松做到线程安全与高效。见第5章。
7. 值语义与数据抽象
本文是11.6“iostream的用途与局限”的后续,在11.6.3“iostream与标准库其他组件的交互”中,我简单地提到了iostream对象和C++标准库中的其他对象(主要是容器和string)具有不同的语义,主要体现在iostream不能拷贝或赋值。下面具体谈一谈我对这个问题的理解。
本文的“对象”定义较为宽泛:a region of memory that has a type,在这个定义下,int、double、bool变量都是对象。
7.1 什么是值语义
值语义(value semantics)指的是对象的拷贝与原对象无关,就像拷贝int一样。C++的内置类型(bool/int/double/char)都是值语义,标准库里的complex<> 、pair<>、vector、map<>、string等等类型也都是值语义,拷贝之后就与原对象脱离关系。Java语言的primitive types也是值语义。
与值语义对应的是“对象语义(object semantics)”,或者叫做引用语义(reference semantics),由于“引用”一词在C++里有特殊含义,所以我在本文中使用“对象语义”这个术语。对象语义指的是面向对象意义下的对象,对象拷贝是禁止的。例如muduo里的Thread是对象语义,拷贝Thread是无意义的,也是被禁止的:因为Thread代表线程,拷贝一个Thread对象并不能让系统增加一个一模一样的线程。
同样的道理,拷贝一个Employee对象是没有意义的,一个雇员不会变成两个雇员,他也不会领两份薪水。拷贝TcpConnection对象也没有意义,系统中只有一个TCP连接,拷贝TcpConnection对象不会让我们拥有两个连接。Printer也是不能拷贝的,系统只连接了一个打印机,拷贝Printer并不能凭空增加打印机。凡此种种,面向对象意义下的“对象”是non-copyable。
Java中的class对象都是对象语义/引用语义。
1 | |
那么a和b指向的是同一个ArrayList对象,修改a同时也会影响b。
值语义与immutable无关。Java有value object一说,按(PoEAA486)的定义,它实际上是immutable object,例如String、Integer、BigInteger、joda.time.DateTime等等(因为Java没有办法实现真正的值语义class,只好用immutable object来模拟)。尽管immutable object有其自身的用处,但不是本文的主题。muduo中的Date、Timestamp也都是immutable的。
C++中的值语义对象也可以是mutable,比如complex<>、pair<>、vector、map<>、string都是可以修改的。muduo的InetAddress和Buffer都具有值语义,它们都是可以修改的。
值语义的对象不一定是POD,例如string就不是POD,但它是值语义的。
值语义的对象不一定小,例如vector<int>的元素可多可少,但它始终是值语义的。当然,很多值语义的对象都是小的,例如complex<>、muduo::Date、muduo::Timestamp。
7.2 值语义与生命期
值语义的一个巨大好处是生命期管理很简单,就跟int一样你不需要操心int的生命期。值语义的对象要么是stack object,要么直接作为其他object的成员,因此我们不用担心它的生命期(一个函数使用自己的stack上的对象,一个成员函数使用自己的数据成员对象)。相反,对象语义的object由于不能拷贝,因此我们只能通过指针或引用来使用它。
一旦使用指针和引用来操作对象,那么就要担心所指的对象是否已被释放,这曾是C++程序bug的一大来源。此外,由于C++只能通过指针或引用来获得多态性,那么在C++里从事基于继承和多态的面向对象编程有其本质的困难——对象生命期管理(资源管理)。
考虑一个简单的对象建模——家长与子女:a Parent has a Child,a Child knows its Parent。在Java中很好写,不用担心内存泄漏,也不用担心空悬指针:
1 | |
只要正确初始化myChild和myParent,那么Java程序员就不用担心出现访问错误。一个handle是否有效,只需要判断其是否non null。
在C++中就要为资源管理费一番脑筋:Parent和Child都代表的是真人,必定是不能拷贝的,因此具有对象语义。Parent是直接持有Child吗?抑或Parent和Child通过指针互指?Child的生命期由Parent控制吗?如果还有ParentClub和School两个class,分别代表家长俱乐部和学校:ParentClub has many Parents,School has many Children,那么如何保证它们始终持有有效的Parent对象和Child对象?何时才能安全地释放Parent和Child?
直接但是易错的写法:
1 | |
如果直接使用指针作为成员,那么如何确保指针的有效性?如何防止出现空悬指针?Child和Parent由谁负责释放?在释放某个Parent对象的时候,如何确保程序中没有指向它的指针?那么释放某个Child对象的时候呢?
这一系列问题曾是C++面向对象编程头疼的问题,不过现在有了smart pointer,我们可以借助smart pointer把对象语义转换为值语义,从而轻松解决对象生命期问题:让Parent持有Child的smart pointer,同时让Child持有Parent的smart pointer,这样始终引用对方的时候就不用担心出现空悬指针。当然,其中一个smart pointer应该是weak reference,否则会出现循环引用,导致内存泄漏。到底哪一个是weak reference,则取决于具体应用场景。
如果Parent拥有Child,Child的生命期由其Parent控制,Child的生命期小于Parent,那么代码就比较简单:
1 | |
在上面这个设计中,Child的指针不能泄露给外界,否则仍然有可能出现空悬指针。
如果Parent与Child的生命期相互独立,就要麻烦一些:
1 | |
上面这个shared_ptr+weak_ptr的做法似乎有点小题大做。
考虑一个稍微复杂一点的对象模型:“a Child has parents: mom and dad; a Parent has one or more Child(ren); a Parent knows his/her spouse.”这个对象模型用Java表述一点都不复杂,垃圾收集会帮我们搞定对象生命期。
1 | |
如果用C++来实现,如何才能避免出现空悬指针,同时避免出现内存泄漏呢?
借助shared_ptr把裸指针转换为值语义,我们就不用担心这两个问题了:
1 | |
如果不使用smart pointer,用C++做面向对象编程将会困难重重。
7.3 值语义与标准库
C++要求凡是能放入标准容器的类型必须具有值语义。准确地说:type必须是SGIAssignable concept的model。但是,由于C++编译器会为class默认提供copy constructor和assignment operator,因此除非明确禁止,否则class总是可以作为标准库的元素类型——尽管程序可以编译通过,但是隐藏了资源管理方面的bug。
因此,在写一个C++ class的时候,让它默认继承boost::noncopyable,几乎总是正确的。
在现代C++中,一般不需要自己编写copy constructor或assignment operator,因为只要每个数据成员都具有值语义的话,编译器自动生成的member-wise copying & assigning就能正常工作;如果以smart ptr为成员来持有其他对象,那么就能自动启用或禁用copying & assigning。例外:编写HashMap这类底层库时还是需要自己实现copy control。
7.4 值语义与C++语言
C++的class本质上是值语义的,这才会出现object slicing这种语言独有的问题,也才会需要程序员注意pass-by-value和pass-by-const-reference的取舍。在其他面向对象编程语言中,这都不需要费脑筋。
值语义是C++语言三大约束之一,C++的设计初衷是让用户定义的类型(class)能像内置类型(int)一样工作,具有同等的地位。为此C++做了以下设计(妥协):
- class的layout与C struct一样,没有额外的开销。定义一个“只包含一个int成员的class”的对象开销和定义一个int一样。
- 甚至class data member都默认是uninitialized,因为函数局部的int也是如此。
- class可以在stack上创建,也可以在heap上创建。因为int可以是stack variable.
- class的数组就是一个个class对象挨着,没有额外的indirection。因为int数组就是这样的。因此派生类数组的指针不能安全转换为基类指针。
- 编译器会为class默认生成copy constructor和assignment operator。其他语言没有copy constructor一说,也不允许重载assignment operator。C++的对象默认是可以拷贝的,这是一个尴尬的特性。
- 当class type传入函数时,默认是make a copy(除非参数声明为reference)因为把int传入函数时是make a copy。
- 当函数返回一个class type时,只能通过make a copy(C++不得不定义RVO来解决性能问题)。因为函数返回int时是make a copy。
- 以class type为成员时,数据成员是嵌入的。例如pair<complex<double>, size_t>的layout就是complex<double>挨着size_t。
这些设计带来了性能上的好处,原因是memory locality。比方说我们在C++里定义complex<double> class,array of complex<double>,vector<complex<double>>,它们的layout如图11-8所示。(re和im分别是复数的实部和虚部。)
而如果我们在Java里干同样的事情,layout大不一样,memory locality也差很多(见图11-9)。
在Java中每个object都有head,在常见的JVM中至少有两个word的开销。对比Java和C++,可见C++的对象模型要紧凑得多。
7.5 什么是数据抽象
本节谈一谈与值语义紧密相关的数据抽象(data abstraction),解释为什么它是与面向对象并列的一种编程范式,为什么支持面向对象的编程语言不一定支持数据抽象。C++在最初的时候以data abstraction为卖点,不过随着时间的流逝,现在似乎很多人只知Object-Oriented,不知data abstraction了。C++的强大之处在于“抽象”不以性能损失为代价,本节我们将看到具体例子。
数据抽象(data abstraction)是与面向对象(object-oriented)并列的一种编程范式(programming paradigm)。说“数据抽象”或许显得陌生,它的另外一个名字“抽象数据类型(abstract data type,ADT)”想必如雷贯耳。
“支持数据抽象”一直是C++语言的设计目标,Bjarne Stroustrup在他的《The C++ Programming Language(第2版)》(1991年出版)中写道:
"The C++ programming language is designed to - be a better C - support data abstraction - support object-oriented programming"
这本书的第3版(1997年出版)增加了一条:
"C++ is a general-purpose programming language with a bias towards systems programming that - is a better C, - supports data abstraction, - supports object-oriented programming, and - supports generic programming."
在C++的早期文献中有一篇Bjarne Stroustrup于1984年写的《Data Abstraction in C++》。在这个页面还能找到Bjarne写的关于C++操作符重载和复数运算的文章,作为数据抽象的详解与范例。可见C++早期是以数据抽象为卖点的,支持数据抽象是C++相对于C的一大优势。
作为语言的设计者,Bjarne把数据抽象作为C++的四个子语言之一。这个观点不是被普遍接受的,比如作为语言的使用者,Scott Meyers在[EC3]中把C++分为四个子语言:C、Object-Oriented C++,Template C++、STL。在Scott Meyers的分类法中,就没有出现数据抽象,而是归入了Object-Oriented C++。
那么到底什么是数据抽象?简单地说,数据抽象是用来描述(抽象)数据结构的。数据抽象就是ADT。一个ADT主要表现为它支持的一些操作,比方说stack::push()、stack::pop(),这些操作应该具有明确的时间和空间复杂度。另外,一个ADT可以隐藏其实现细节,例如stack既可以用动态数组实现,又可以用链表实现。
按照这个定义,数据抽象和基于对象(object-based)很像,那么它们的区别在哪里?语义不同。ADT通常是值语义,而object-based是对象语义。(这两种语义的定义见11.7.1“什么是值语义”)。ADT class是可以拷贝的,拷贝之后的instance与原instance脱离关系。
比方说
1 | |
这时候a里仍然有元素10。
C++标准库中的数据抽象
C++标准库中的complex、pair<>、vector<>、list<>、map、set、string、stack、queue都是数据抽象的例子。vector是动态数组,它的主要操作有size()、begin()、end()、push_back()等等,这些操作不仅含义清晰,而且计算复杂度都是常数。类似地,list是链表,map是有序关联数组,set是有序集合、stack是FILO栈、queue是FIFO队列。“动态数组”、“链表”、“有序集合”、“关联数组”、“栈”、“队列”都是定义明确(操作、复杂度)的抽象数据类型。
数据抽象与面向对象的区别
本文把data abstraction、object-based、object-oriented视为三个编程范式。这种细致的分类或许有助于理解区分它们之间的差别。
通俗地讲,面向对象(object-oriented)有三大特征:封装、继承、多态。而基于对象(object-based)则只有封装,没有继承和多态,即只有具体类,没有抽象接口。它们两个都是对象语义。
面向对象真正核心的思想是消息传递(messaging),“封装继承多态”只是表象。关于这一点,孟岩和王益都有精彩的论述,笔者不再赘言。
数据抽象与它们两个的界限在于“语义”,数据抽象不是对象语义,而是值语义。比方说muduo里的TcpConnection和Buffer都是具体类,但前者是基于对象的(object-based),而后者是数据抽象。
类似地,muduo::Date、muduo::Timestamp都是数据抽象。尽管这两个class简单到只有一个int/long数据成员,但是它们各自定义了一套操作(operation),并隐藏了内部数据,从而让它从data aggregation变成了data abstraction.
数据抽象是针对“数据”的,这意味着ADT class应该可以拷贝,只要把数据复制一份就行了。如果一个class代表了其他资源(文件、员工、打印机、账号),那么它通常就是object-based或object-oriented,而不是数据抽象。
ADT class可以作为Object-based/object-oriented class的成员,但反过来不成,因为这样一来ADT class的拷贝就失去意义了。
7.6 数据抽象所需的语言设施
不是每个语言都支持数据抽象,下面简要列出“数据抽象”所需的语言设施。
支持数据聚合
数据聚合即data aggregation,或者叫value aggregates。即定义C-style struct,把有关数据放到同一个struct里。FORTRAN 77没有这个能力,FORTRAN 77无法实现ADT。这种数据聚合struct是ADT的基础,struct List、struct HashTable等能把链表和哈希表结构的数据放到一起,而不是用几个零散的变量来表示它。
全局函数与重载
例如我定义了complex,那么我可以同时定义complex sin(const complex& x)和complex exp(const complex& x)等等全局函数来实现复数的三角函数和指数运算。sin()和exp()不是complex的成员,而是全局函数double sin(double)和double exp(double)的重载。这样能让double a = sin(b);和complex a = sin(b);具有相同的代码形式,而不必写成complex a = b.sin()。
C语言可以定义全局函数,但是不能与已有的函数重名,也就没有重载。Java没有全局函数,而且Math class是封闭的,并不能往其中添加sin(Complex)。
成员函数与private数据
数据也可以声明为private,防止外界意外修改。不是每个ADT都适合把数据声明为private,例如complex、Point、pair<>这样的ADT使用public data更加合理。
要能够在struct里定义操作,而不是只能用全局函数来操作struct。比方说vector有push_back()操作,push_back是vector的一部分,它必须直接修改vector的private data members,因此无法定义为全局函数。
这两点其实就是定义class,现在的语言都能直接支持,C语言除外。
拷贝控制(copy control)
copy control是拷贝stack a; stack b = a;和赋值stack b; b = a;的合称。
当拷贝一个ADT时会发生什么?比方说拷贝一个stack,是不是应该把它的每个元素按值拷贝到新stack?
如果语言支持显示控制对象的生命期(比方说C++的确定性析构),而ADT用到了动态分配的内存,那么copy control更为重要,可防止访问已经失效的对象。
由于C++ class是值语义,copy control是实现深拷贝的必要手段,而且ADT用到的资源只涉及动态分配的内存,所以深拷贝是可行的。相反,object-based编程风格中的class往往代表某样真实的事物(Employee、Account、File等等),深拷贝无意义。
C语言没有copy control,也没有办法防止拷贝,一切要靠程序员自己小心在意。
FILE*可以随意拷贝,但是只要关闭其中一个copy,其他copy也都失效了,跟空悬指针一般。整个C语言对待资源(malloc得到的内存,open()打开的文件,socket()打开的连接)都是这样的,用整数或指针来代表(即“句柄”)。而整数和指针类型的“句柄”是可以随意拷贝的,很容易就造成重复释放、遗漏释放、使用已经释放的资源等等常见错误。这方面C++是一个显著的进步,我认为boost::noncopyable是Boost里最值得推广的库。
操作符重载
如果要写动态数组,我们希望能像使用内置数组一样使用它,比如支持下标操作。C++可以重载operator[]来做到这一点。
如果要写复数,我们希望能像使用内置的double一样使用它,比如支持加减乘除。C++可以重载operator+等操作符来做到这一点。
如果要写日期与时间,我们希望它能直接用大于或小于号来比较先后,用==来判断是否相等。C++可以重载operator<等操作符来做到这一点。
这要求语言能重载成员与全局操作符。操作符重载是C++与生俱来的特性,1984年的CFront 1.0就支持操作符重载,并且提供了一个complex class,这个class与目前标准库的complex<>在使用上无区别。
如果没有操作符重载,那么用户定义的ADT与内置类型用起来就不一样了(想想有的语言要区分==和equals,代码写起来实在很累赘)。Java里有BigInteger,但是BigInteger用起来和普通int/long大不相同:
1 | |
当然,操作符重载容易被滥用,因为这样显得很“酷”。我认为只在ADT表示一个“数值”的时候才适合重载加减乘除,其他情况下用具名函数为好,因此muduo::Timestamp只重载了关系操作符,没有重载加减操作符。另外一个理由见12.6“采用有利于版本管理的代码格式”。
效率无损
“抽象”不代表低效。在C++中,提高抽象的层次并不会降低效率。不然的话,人们宁可在低层次上编程,而不愿使用更便利的抽象,数据抽象也就失去了市场。后面我们将看到一个具体的例子。
模板与泛型
如果我写了一个IntVector,那么我不想为double和string再实现一遍同样的代码。我应该把vector写成template,然后用不同的类型来具现化它,从而得到vector<int>、vector<double>、vector<complex>、vector<string>等具体类型。
不是每个ADT都需要这种泛型能力,一个Date class就没必要让用户指定该用哪种类型的整数,int32_t足够了。
根据上面的要求,不是每个面向对象语言都能原生支持数据抽象,也说明数据抽象不是面向对象的子集。
7.7 数据抽象的例子
下面我们看看数值模拟N-body问题的两个程序,前一个是用C语言,后一个是用C++语言。这个例子来自编程语言的性能对比网站。两个程序使用的算法相同。
C语言版
完整代码见recipes/puzzle/file_nbody.c,下面是核心代码。struct planet保存行星位置、速度、质量,位置和速度各有三个分量。程序模拟几大行星在三维空间中受引力支配的运动。
其中最核心的算法是advance()函数实现的数值积分,它根据各个星球之间的距离和引力,算出加速度,再修正速度,然后更新星球的位置。这个naive算法的复杂度是O(N^2)。
1 | |
C++数据抽象版
完整代码见recipes/puzzle/file_nbody.cc,下面是其代码骨架。首先定义Vector3这个抽象,代表三维向量,它既可以是位置,又可以是速度。本处略去了Vector3的操作符重载(Vector3支持常见的向量加减乘除运算)。然后定义Planet这个抽象,代表一个行星,它有两个Vector3成员:位置和速度。需要说明的是,按照语义,Vector3是数据抽象,而Planet是object-based。
1 | |
相同功能的advance()代码则简短得多,而且更容易验证其正确性。(设想假如把C语言版的advance()中的vx、vy、vz、dx、dy、dz写错位了,这种错误较难发现。)
1 | |
尽管C++使用了更高层的抽象Vector3,但它的性能和C语言一样快。看看memory layout就会明白。
C struct的成员是连续存储的,struct数组也是连续的。
尽管C++定义了Vector3这个抽象,但它的内存布局并没有改变。C++ Planet的布局和C planet一模一样,Planet[]的布局也和C数组一样。
另一方面,C++的inline函数在这里也起了巨大作用,我们可以放心地调用Vector3::operator+=(等操作符,编译器会生成和C一样高效的代码。
不是每个编程语言都能做到在提升抽象的时候不影响性能,来看看Java的内存布局。如果我们用class Vector3、class Planet、Planet[]的方式写一个Java版的N-body程序,内存布局将会是如图11-12所示的样子。这样大大降低了memory locality,有兴趣的读者可以对比Java和C++的实现效率。
用更高级和底层的优化,复杂度是O(NlogN),在大规模模拟时其运行速度也比本naive算法快得多。
更多的例子
- Date与Timestamp
这两个class的“数据”都是整数,各定义了一套操作,用于表达日期与时间这两个概念。
- BigInteger
它本身就是一个“数”。如果用C++实现BigInteger,那么阶乘函数写出来十分自然。下面第二个函数是Java语言的版本。
1 | |
1 | |
高精度运算库gmp有一套高质量的C++封装。
图形学中的三维齐次坐标Vector4和对应的4×4变换矩阵Matrix4
金融领域中经常成对出现的“买入价/卖出价”
可以封装为BidOffer struct,这个struct的成员可以有mid()(中间价)、spread()(买卖差价)、加减操作符等等。
小结
数据抽象是C++的重要抽象手段,适合封装“数据”,它的语义简单,容易使用。数据抽象能简化代码书写,减少偶然错误。
在新写一个class的时候,先想清楚它是值语义还是对象语义。一般来说,一个项目里只有少量的class是值语义,比如一些snapshot的数据,而大多数class都是对象语义。
如果是对象语义的class,那么应该立刻继承boost::noncopyable,防止编译器自动生成的拷贝构造函数和赋值操作符在无意中破坏程序行为。