2.4.1 字符串与切片
1 字符串
1.1 切片(slice)
切片并不是 Rust 独有的概念,在 Go 语言中就非常流行,它允许你引用集合中部分连续的元素序列,而不是引用整个集合。
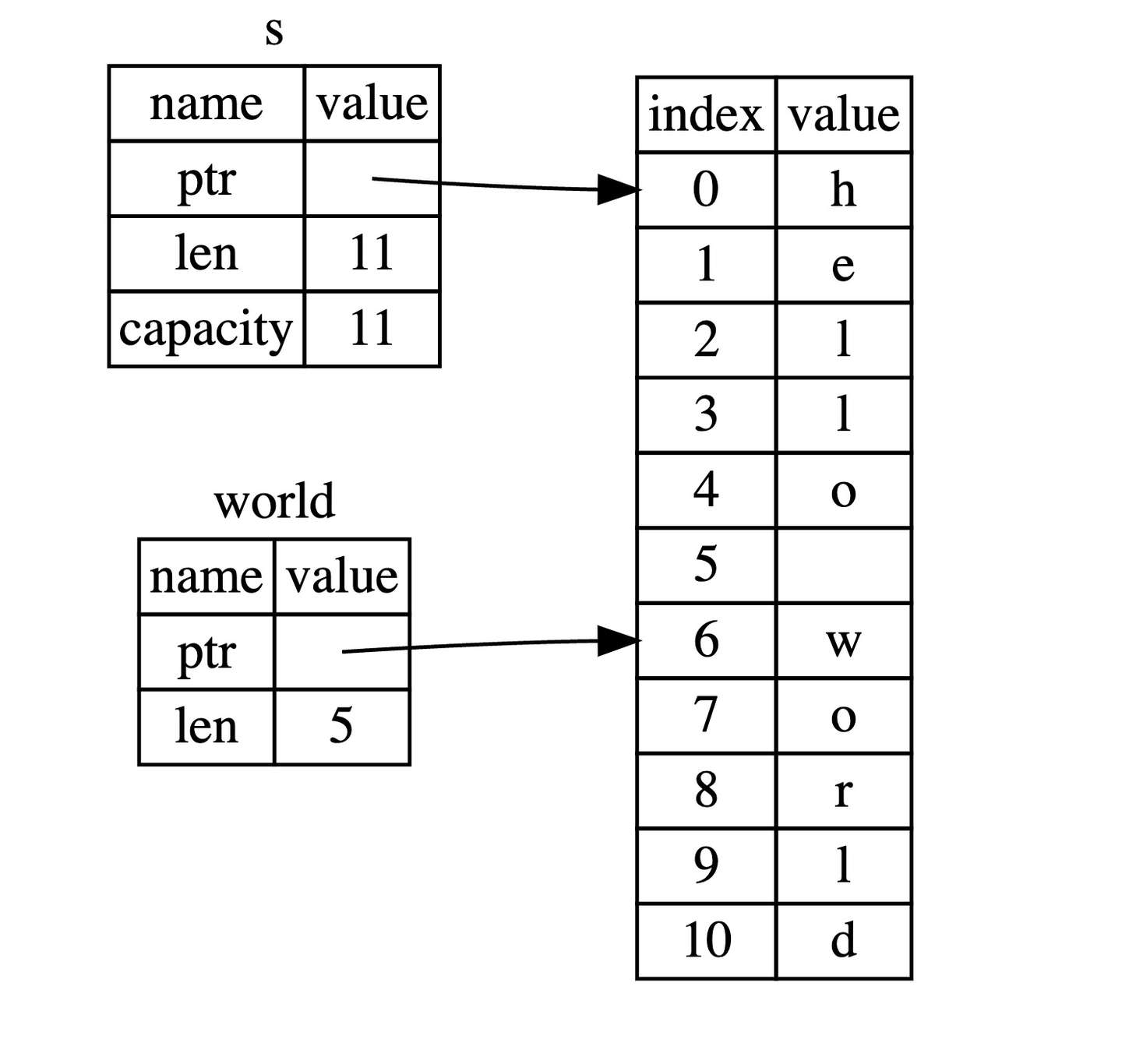
对于字符串而言,切片就是对 String
类型中某一部分的引用,它看起来像这样:
1 | |
hello 没有引用整个 String s,而是引用了
s 的一部分内容,通过 [0..5] 的方式来指定。
这就是创建切片的语法,使用方括号包括的一个序列:[开始索引..终止索引),其中开始索引是切片中第一个元素的索引位置,而终止索引是最后一个元素后面的索引位置。换句话说,这是一个
右半开区间(或称为左闭右开区间)——指的是在区间的左端点是包含在内的,而右端点是不包含在内的。在切片数据结构内部会保存开始的位置和切片的长度,其中长度是通过
终止索引 - 开始索引 的方式计算得来的。
对于 let world = &s[6..11]; 来说,world
是一个切片,该切片的指针指向 s 的第 7 个字节(索引从 0 开始,
6 是第 7 个字节),且该切片的长度是 5 个字节。
在使用 Rust 的 .. range 序列语法时,如果你想从索引 0
开始,可以使用如下的方式,这两个是等效的:
1 | |
同样的,如果你的切片想要包含 String
的最后一个字节,则可以这样使用:
1 | |
你也可以截取完整的 String 切片:
1 | |
在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是 UTF-8 字符的边界,例如中文在 UTF-8 中占用三个字节,下面的代码就会崩溃:
2
3let s = "中国人";
let a = &s[0..2];
println!("{}",a);因为我们只取
s字符串的前两个字节,但是本例中每个汉字占用三个字节,因此没有落在边界处,也就是连中字都取不完整,此时程序会直接崩溃退出,如果改成&s[0..3],则可以正常通过编译。
字符串切片的类型标识是
&str,因此我们可以这样声明一个函数,输入
String 类型,返回它的切片:
fn first_word(s: &String) -> &str。
有了切片就可以写出这样的代码:
1 | |
1.1.1 其它切片
因为切片是对集合的部分引用,因此不仅仅字符串有切片,其它集合类型也有,例如数组:
1 | |
该数组切片的类型是
&[i32],数组切片和字符串切片的工作方式是一样的,例如持有一个引用指向原始数组的某个元素和长度。
2 字符串字面量是切片
之前提到过字面量,但是没有提到它的类型:
1 | |
实际上,s 的类型是
&str,因此你也可以这样声明:
1 | |
该切片指向了程序可执行文件中的某个点,这也是为什么字符串字面量是不可变的,因为
&str 是一个不可变引用。
3 什么是字符串?
顾名思义,字符串是由字符组成的连续集合,但是在上一节中我们提到过,Rust 中的字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间,但是字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的(1 - 4),这样有助于大幅降低字符串所占用的内存空间。
Rust
在语言级别,只有一种字符串类型:str,它通常是以引用类型出现
&str,也就是上文提到的字符串切片。虽然语言级别只有上述的
str
类型,但是在标准库里,还有多种不同用途的字符串类型,其中使用最广的是
String 类型。
str 类型是硬编码进可执行文件,也无法被修改,但是
String 则是一个可增长、可改变且具有所有权的 UTF-8
编码字符串,当 Rust 用户提到字符串时,往往指的是
String 类型和 &str
字符串切片类型,这两个类型都是 UTF-8 编码。
除了 String 类型的字符串,Rust
的标准库还提供了其他类型的字符串,例如
OsString,OsStr,CsString 和
CsStr 等,注意到这些名字都以 String 或者
Str
结尾了吗?它们分别对应的是具有所有权和被借用的变量。
4 String 与 &str 的转换
在之前的代码中,已经见到好几种从 &str 类型生成
String 类型的操作:
String::from("hello,world")"hello,world".to_string()
那么如何将 String 类型转为 &str
类型呢?答案很简单,取引用即可:
1 | |
实际上这种灵活用法是因为 deref
隐式强制转换,具体我们会在 Deref 特征 进行详细讲解。
5 字符串索引
在其它语言中,使用索引的方式访问字符串的某个字符或者子串是很正常的行为,但是在 Rust 中就会报错:
1 | |
5.1 深入字符串内部
字符串的底层数据存储格式实际上是 u8
数组,一个字节数组。对于 let hello = String::from("Hola");
这行代码来说,Hola 的长度是 4 个字节,因为
"Hola" 中的每个字母在 UTF-8 编码中仅占用 1
个字节,但是对于下面的代码呢?
1 | |
如果问你该字符串多长,你可能会说 3,但是实际上是
9 个字节的长度,因为大部分常用汉字在 UTF-8 中的长度是
3 个字节,因此这种情况下对 hello
进行索引,访问 &hello[0] 没有任何意义,因为你取不到
中
这个字符,而是取到了这个字符三个字节中的第一个字节,这是一个非常奇怪而且难以理解的返回值。
5.2 字符串的不同表现形式
现在看一下用梵文写的字符串 “नमस्ते”,
它底层的字节数组如下形式:
1 | |
长度是 18 个字节,这也是计算机最终存储该字符串的形式。如果从字符的形式去看,则是:
1 | |
但是这种形式下,第四和六两个字母根本就不存在,没有任何意义,接着再从字母串的形式去看:
1 | |
所以,可以看出来 Rust 提供了不同的字符串展现方式,这样程序可以挑选自己想要的方式去使用,而无需去管字符串从人类语言角度看长什么样。
还有一个原因导致了 Rust
不允许去索引字符串:因为索引操作,我们总是期望它的性能表现是
O(1),然而对于 String 类型来说,无法保证这一点,因为 Rust
可能需要从 0 开始去遍历字符串来定位合法的字符。
6 操作字符串
由于 String 是可变字符串,下面介绍 Rust
字符串的修改,添加,删除等常用方法:
6.1 追加 (Push)
在字符串尾部可以使用 push() 方法追加字符
char,也可以使用 push_str()
方法追加字符串字面量。这两个方法都是
在原有的字符串上追加,并不会返回新的字符串。由于字符串追加操作要修改原来的字符串,则该字符串必须是可变的,即
字符串变量必须由 mut 关键字修饰。
示例代码如下:
1 | |
代码运行结果:
1 | |
6.2 插入 (Insert)
可以使用 insert() 方法插入单个字符
char,也可以使用 insert_str()
方法插入字符串字面量,与 push()
方法不同,这俩方法需要传入两个参数,
- 第一个参数是字符(串)插入位置的索引,
- 第二个参数是要插入的字符(串),索引从 0 开始计数,如果越界则会发生错误。
由于字符串插入操作要
修改原来的字符串,则该字符串必须是可变的,即
字符串变量必须由 mut 关键字修饰。
示例代码如下:
1 | |
代码运行结果:
1 | |
6.3 替换 (Replace)
如果想要把字符串中的某个字符串替换成其它的字符串,那可以使用
replace() 方法。与替换有关的方法有三个。
1、 replace
该方法可适用于 String 和 &str 类型。
replace()
方法接收两个参数,第一个参数是要被替换的字符串,第二个参数是新的字符串。该方法会替换所有匹配到的字符串。
该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
1 | |
代码运行结果:
1 | |
2、 replacen
该方法可适用于 String 和 &str 类型。
replacen() 方法接收三个参数,前两个参数与
replace() 方法一样,第三个参数则表示替换的个数。
该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
1 | |
代码运行结果:
1 | |
3、 replace_range
该方法仅适用于 String 类型。 replace_range
接收两个参数,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符串。
该方法是直接操作原来的字符串,不会返回新的字符串。该方法需要使用
mut 关键字修饰。
示例代码如下:
1 | |
代码运行结果:
1 | |
6.4 删除 (Delete)
与字符串删除相关的方法有 4 个,它们分别是
pop(),remove(),truncate(),clear()。这四个方法仅适用于
String 类型。
1、 pop —— 删除并返回字符串的最后一个字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是一个
Option 类型,如果字符串为空,则返回 None。
示例代码如下:
1 | |
代码运行结果:
1 | |
2、 remove —— 删除并返回字符串中指定位置的字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是删除位置的字符串,只接收一个参数,表示该字符起始索引位置。remove()
方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
1 | |
代码运行结果:
1 | |
3、 truncate ——
删除字符串中从指定位置开始到结尾的全部字符
该方法是直接操作原来的字符串。无返回值。该方法
truncate()
方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
1 | |
代码运行结果:
1 | |
4、 clear —— 清空字符串
该方法是直接操作原来的字符串。调用后,删除字符串中的所有字符,相当于
truncate() 方法参数为 0 的时候。
示例代码如下:
1 | |
代码运行结果:
1 | |
6.5 连接 (Concatenate)
1、使用 + 或者 += 连接字符串
使用 + 或者 +=
连接字符串,要求右边的参数必须为字符串的切片引用(Slice)类型。其实当调用
+ 的操作符时,相当于调用了 std::string
标准库中的 add() 方法,这里 add()
方法的第二个参数是一个引用的类型。因此我们在使用 +
时,必须传递切片引用类型。不能直接传递 String
类型。 +
是返回一个新的字符串,所以变量声明可以不需要 mut
关键字修饰。
示例代码如下:
1 | |
代码运行结果:
1 | |
add() 方法的定义:
1 | |
因为该方法涉及到更复杂的特征功能,因此我们这里简单说明下:
1 | |
self 是 String 类型的字符串
s1,该函数说明,只能将 &str
类型的字符串切片添加到 String 类型的 s1
上,然后返回一个新的 String 类型,所以
let s3 = s1 + &s2; 就很好解释了,将 String
类型的 s1 与 &str 类型的 s2
进行相加,最终得到 String 类型的 s3。
由此可推,以下代码也是合法的:
1 | |
String + &str 返回一个
String,然后再继续跟一个 &str 进行
+ 操作,返回一个 String
类型,不断循环,最终生成一个 s,也是 String
类型。
s1 这个变量通过调用 add()
方法后,所有权被转移到 add() 方法里面,add()
方法调用后就被释放了,同时 s1 也被释放了。再使用
s1 就会发生错误。这里涉及到 所有权转移(Move)
的相关知识。
2、使用 format! 连接字符串
format! 这种方式适用于 String 和
&str 。format! 的用法与
print! 的用法类似,详见 格式化输出。
示例代码如下:
1 | |
代码运行结果:
1 | |
7 字符串转义
我们可以通过转义的方式 \ 输出 ASCII 和 Unicode
字符。
1 | |
当然,在某些情况下,可能你会希望保持字符串的原样,不要转义:
1 | |
8 操作 UTF-8 字符串
8.1 字符
如果你想要以 Unicode 字符的方式遍历字符串,最好的办法是使用
chars 方法,例如:
1 | |
输出如下
1 | |
8.2 字节
这种方式是返回字符串的底层字节数组表现形式:
1 | |
输出如下:
1 | |
8.3 获取子串
想要准确的从 UTF-8 字符串中获取子串是较为复杂的事情,例如想要从
holla中国人नमस्ते
这种变长的字符串中取出某一个子串,使用标准库你是做不到的。 你需要在
crates.io 上搜索 utf8 来寻找想要的功能。
可以考虑尝试这个库: utf8_slice。
9 字符串深度剖析
那么问题来了,为啥 String 可变,而字符串字面值
str 却不可以?
就字符串字面值来说,我们在编译时就知道其内容,最终字面值文本被直接硬编码进可执行文件中,这使得字符串字面值快速且高效,这主要得益于字符串字面值的不可变性。不幸的是,我们不能为了获得这种性能,而把每一个在编译时大小未知的文本都放进内存中(你也做不到!),因为有的字符串是在程序运行的过程中动态生成的。
对于 String
类型,为了支持一个可变、可增长的文本片段,需要在堆上分配一块在编译时未知大小的内存来存放内容,这些都是在程序运行时完成的:
- 首先向操作系统请求内存来存放
String对象 - 在使用完成后,将内存释放,归还给操作系统
其中第一部分由 String::from 完成,它创建了一个全新的
String。
重点来了,到了第二部分,就是百家齐放的环节,在有垃圾回收 GC 的语言中,GC 来负责标记并清除这些不再使用的内存对象,这个过程都是自动完成,无需开发者关心,非常简单好用;但是在无 GC 的语言中,需要开发者手动去释放这些内存对象,就像创建对象需要通过编写代码来完成一样,未能正确释放对象造成的后果简直不可估量。
对于 Rust 而言,安全和性能是写到骨子里的核心特性,如果使用 GC,那么会牺牲性能;如果使用手动管理内存,那么会牺牲安全,这该怎么办?为此,Rust 的开发者想出了一个无比惊艳的办法:变量在离开作用域后,就自动释放其占用的内存:
1 | |
与其它系统编程语言的 free 函数相同,Rust
也提供了一个释放内存的函数:
drop,但是不同的是,其它语言要手动调用 free
来释放每一个变量占用的内存,而 Rust 则在变量离开作用域时,自动调用
drop 函数:上面代码中,Rust 在结尾的 }
处自动调用 drop。
其实,在 C++ 中,也有这种概念:Resource Acquisition Is Initialization (RAII)。如果你使用过 RAII 模式的话应该对 Rust 的
drop函数并不陌生。
这个模式对编写 Rust 代码的方式有着深远的影响,在后面章节我们会进行更深入的介绍。