给定一个链表的第一个节点 head
,找到链表中所有出现多于一次的元素,并删除这些元素所在的节点。
返回删除后的链表。
示例 1:
 img
img
1
2
3
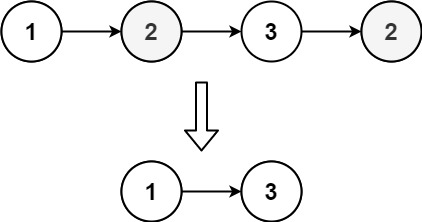
| 输入: head = [1,2,3,2]
输出: [1,3]
解释: 2 在链表中出现了两次,所以所有的 2 都需要被删除。删除了所有的 2 之后,我们还剩下 [1,3] 。
|
示例 2:
 img
img
1
2
3
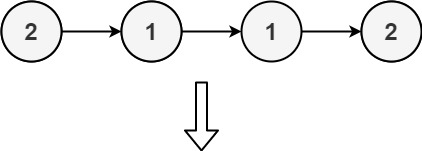
| 输入: head = [2,1,1,2]
输出: []
解释: 2 和 1 都出现了两次。所有元素都需要被删除。
|
示例 3:
 img
img
1
2
3
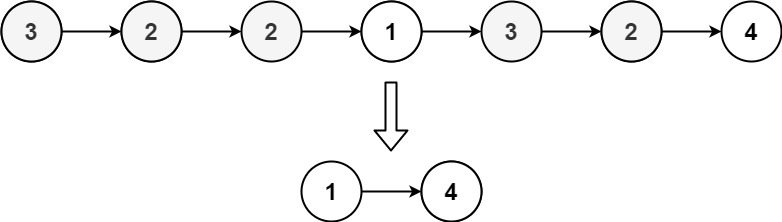
| 输入: head = [3,2,2,1,3,2,4]
输出: [1,4]
解释: 3 出现了两次,且 2 出现了三次。移除了所有的 3 和 2 后,我们还剩下 [1,4] 。
|
提示:
- 链表中节点个数的范围是
[1, 105]
1 <= Node.val <= 105
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| #include <unordered_map>
class Solution {
public:
ListNode* deleteDuplicatesUnsorted(ListNode* head) {
std::unordered_map<int, int> count;
ListNode* p = head;
while (p != nullptr) {
count[p->val]++;
p = p->next;
}
ListNode* dummy = new ListNode(0);
dummy->next = head;
p = dummy;
while (p->next != nullptr) {
ListNode* unique = p->next;
while (unique != nullptr && count[unique->val] > 1) {
ListNode* temp = unique;
unique = unique->next;
delete temp;
}
if (unique == nullptr) {
p->next = nullptr;
break;
} else {
p->next = unique;
}
p = p->next;
}
ListNode* result = dummy->next;
delete dummy;
return result;
}
};
|