1.3 三种交换方式 1.3 三种交换方式 1. 电路交换(Circuit Switching) 电话交换机接通电话线的方式称为电路交换,中间设备是电话交换机 从通信资源的分配角度来看,交换(Switching)就是按照某种方式动态地分配传输线路的资源; 当使用电路交换来传送计算机数据时,其线路的传输效率往往很低。 不适合计算机传输数据,因为占用通信资源,却迟迟不使用,造成通信资源的浪费 电 2024-11-15 计算机基础 > 计算机网络 #计算机网络
HCTA:多智能体强化学习中的分层合作任务分配 HCTA:Hierarchical Cooperative Task Allocation in Multi-Agent Reinforcement Learning 1. 主要内容 子任务选择: 基于行动链的长期行为特征动态选择每个智能体适合的子任务。 层次化策略学习: 结合上述子任务分解和选择,形成层次化合作策略学习框架。在上层动态选择子任务,并在下层根 2024-11-15 科研 > 多智能体强化学习任务分配 #RL #科研
面向兵棋推演的强化学习分层任务优化技术研究 1. 主要内容 论文深入探讨了分层控制结构的多智能体强化学习算法在兵棋推演环境中的应用,旨在优化复杂和不确定环境下的任务分配和多智能体任务的执行过程。主要研究内容包括: 针对实时兵棋推演环境,设计了兵棋AI的状态空间和动作空间,并生成了敌我对抗态势的关键特征信息。通过离散化连续动作的操作优化了原始动作空间,简化了多智能体的交互过程,加快了网络学习速度。 提出了一种融合注意力机制的DQN算 2024-11-15 科研 > 多智能体强化学习任务分配 #RL #科研
基于分层强化学习的多智能体博弈对抗策略 1. 主要内容 1.1 研究内容 提出了一种结合任务可解释性的指挥官-集群多智能体分层强化学习算法,提高算法在复杂博弈场景中的收敛速度。 设计了一种结合软决策树的多智能体分层强化学习算法,增强了策略的解释性。 基于模糊决策树建立了博弈对抗策略,通过挖掘战法规则,模拟人的决策过程。 在联合作战实验平台上设计了空战博弈场景和海空联合作战场景,验证了所提算法的有效性。 1.2 算法设 2024-11-15 科研 > 多智能体强化学习任务分配 #RL #科研
基于多智能体强化学习的分层决策优化方法 1. 主要内容 背景与目的: 随着信息技术和人工智能的发展,大数据驱动的辅助决策方法变得更加科学和准确。 强化学习在决策优化方面具有优势,但传统方法难以解决多层次、多目标的决策优化问题,尤其是在长周期决策优化问题中,学习奖励的滞后性限制了效率。 方法论: 提出基于多智能体强化学习的分层决策优化方法,应用目标分解思想解决长期决策优化问题。 该方法基于强化学习理论,使具有层 2024-11-15 科研 > 多智能体强化学习任务分配 #RL #科研
基于层次控制的多智能体对抗研究 1. 主要内容 针对复杂动作状态空间场景下单智能体策略学习问题,提出了一种基于预训练模型的分层强化学习算法。该算法分为三个层次: 首先,基于先验知识为每个子策略设计了适宜其相应时间的宏动作; 其次是子策略控制器,其核心是基于监督学习的方法,训练能够适应不同需要的子策略,基于随机的宏动作产生子策略监督学习的数据,并且子策略只学习胜利时的操作轨迹; 最后是智能体的高级策略控制器,基于策 2024-11-14 科研 > 多智能体强化学习任务分配 #RL #科研
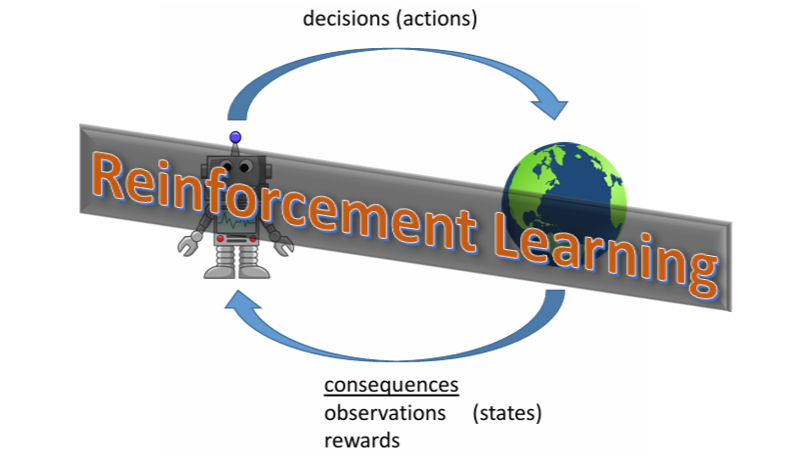
3.3 无监督学习-强化学习-吴恩达 强化学习 状态、动作、奖励和下一个状态(s, a, R(s), s') 1. 回报 折扣因子 2. 决策 马尔可夫决策过程 MDP 在马尔可夫决策过程中,未来只取决于你现在所处的位置,而不取决于你是如何到达这里的。 3. 状态-动作价值函数 3.1 贝尔曼方程 如果你从状态s 开始,你将采取行动a,然后在此之后 2024-11-14 AI > ML > ML-吴恩达 #ML
3.2 无监督学习-推荐系统-吴恩达 推荐系统 1. 使用每个特征数据 2. 协同过滤算法 假设已经有了w和b,猜测特征x 这种协同过滤是从多个用户收集数据,用户之间的这种协作可帮助您预测未来甚至其他用户的评级。 推荐系统的一个非常常见的用例是当您有二进制标签时,例如用户喜欢、喜欢或与项目交互的标签。 3.二进制标签 分类不用正则化 4. 均值归一 2024-11-14 AI > ML > ML-吴恩达 #ML
3.1 无监督学习-无监督学习-吴恩达 无监督学习 1. 聚类 1.1 k-means 如果一个集群训练样本为零,可以消除该集群,最终得到k-1;另一种方法是重新初始化该集群质心 1.2 优化目标 1.3 初始化 1.4 选择聚类数量 肘法 2. 异常检测 2.1 密度估计 2.2 高斯正态分布 最大似然估计 2.3 异常检测算法 2. 2024-11-14 AI > ML > ML-吴恩达 #ML
2.4 深度学习-决策树-吴恩达 决策树 根节点 决策节点 叶节点 决策树学习算法的工作是,从所有可能的决策树中,尝试选择一个希望在训练集上表现良好的树,然后理想地泛化到新数据,例如交叉验证和测试集 1. 学习过程 决策树学习的第一步是,我们必须决定在根节点使用什么特征。 决策 2:何时停止分裂? 当一个节点完全是一类时 当分裂一个节点会导致树超过最大深度时 当纯度分数的提高低于 2024-11-14 AI > ML > ML-吴恩达 #ML